Что такое обработка естественного языка? – NLP – AWS
Что такое NLP?
Обработка естественного языка (NLP) – это технология машинного обучения, которая дает компьютерам возможность интерпретировать, манипулировать и понимать человеческий язык. Сегодня организации имеют большие объемы голосовых и текстовых данных из различных каналов связи, таких как электронные письма, текстовые сообщения, новостные ленты социальных сетей, видео, аудио и многое другое. Они используют программное обеспечение NLP для автоматической обработки этих данных, анализа намерений или настроений в сообщении и реагирования на человеческое общение в режиме реального времени.
Почему NLP играет такую важную роль?
Обработка естественного языка имеет решающее значение для эффективного анализа текстовых и речевых данных. Таким образом можно преодолевать различия в диалектах, сленге и грамматических нарушениях, типичных для повседневных разговоров. Компании используют этот метод для нескольких автоматизированных задач, таких как:
• Обработка, анализ и архивирование больших документов
• Анализ отзывов клиентов или записей колл-центра
• Запуск чат-ботов для автоматизированного обслуживания клиентов
• Ответы на вопросы «кто, что, когда и где»
• Классификация и извлечение текста
Вы также можете интегрировать NLP в приложения, ориентированные на клиента, чтобы более эффективно общаться с клиентами. Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает снизить затраты, избавить агентов от необходимости тратить время на избыточные запросы и повышает удовлетворенность клиентов.
Например, чат-бот анализирует и сортирует запросы клиентов, автоматически отвечая на распространенные вопросы и перенаправляя сложные запросы в службу поддержки. Эта автоматизация помогает снизить затраты, избавить агентов от необходимости тратить время на избыточные запросы и повышает удовлетворенность клиентов.
Каковы сценарии использования NLP для бизнеса?
Компании используют программное обеспечение и инструменты NLP для эффективного и точного упрощения, автоматизации и оптимизации операций. Ниже мы приводим несколько примеров использования.
Скрытие конфиденциальных данныхКомпании в страховом, юридическом и медицинском секторах обрабатывают, сортируют и извлекают большие объемы конфиденциальных документов, таких как медицинские карты, финансовые данные и личные данные. Вместо проверки вручную компании используют технологию NLP для редактирования личной информации и защиты конфиденциальных данных. Например, Chisel AI помогает страховым компаниям извлекать номера полисов, даты истечения срока действия и другие личные атрибуты клиентов из неструктурированных документов с помощью Amazon Comprehend.![]()
Технологии NLP позволяют чат-ботам и голосовым ботам быть более похожими на людей при общении с клиентами. Компании используют чат-ботов для масштабирования возможностей и качества обслуживания клиентов при минимальных эксплуатационных расходах. Компания PubNub, которая создает программное обеспечение для чат-ботов, использует Amazon Comprehend для внедрения локализованных функций чата для своих клиентов по всему миру. T-Mobile использует NLP для определения конкретных ключевых слов в текстовых сообщениях клиентов и предоставления персонализированных рекомендаций. Университет штата Оклахома внедряет чат-бот для вопросов и ответов для решения вопросов студентов с использованием технологии машинного обучения (ML)
Бизнес-аналитикаМаркетологи используют инструменты NLP, такие как Amazon Comprehend и Amazon Lex, чтобы получить образованное представление о том, что клиенты чувствуют к продукту или сервисам компании. Сканируя определенные фразы, они могут оценить настроение и эмоции клиента в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях анализа тональности и помогают контакт-центрам получать полезную информацию из аналитики звонков.
Сканируя определенные фразы, они могут оценить настроение и эмоции клиента в письменных отзывах. Например, Success KPI предоставляет решения для обработки естественного языка, которые помогают компаниям сосредоточиться на целевых областях анализа тональности и помогают контакт-центрам получать полезную информацию из аналитики звонков.
Как работает NLP?
Обработка естественного языка сочетает в себе компьютерную лингвистику, машинное обучение и модели глубокого обучения для обработки человеческого языка.
Компьютерная лингвистикаКомпьютерная лингвистика – это наука о понимании и построении моделей человеческого языка с помощью компьютеров и программных инструментов. Исследователи используют методы компьютерной лингвистики, такие как синтаксический и семантический анализ, для создания платформ, помогающих машинам понимать разговорный человеческий язык. Такие инструменты, как переводчики языков, синтезаторы текста в речь и программное обеспечение для распознавания речи, основаны на компьютерной лингвистике.
Машинное обучение – это технология, которая обучает компьютер с помощью выборочных данных для повышения его эффективности. Человеческий язык имеет несколько особенностей, таких как сарказм, метафоры, вариации в структуре предложений, а также исключения из грамматики и употребления, на изучение которых у людей уходят годы. Программисты используют методы машинного обучения, чтобы научить приложения NLP распознавать и точно понимать эти функции с самого начала.
Глубокое обучениеГлубокое обучение – это особая область машинного обучения, которая учит компьютеры учиться и мыслить как люди. Это включает нейросеть, состоящую из узлов обработки данных, напоминающих операции человеческого мозга. С помощью глубокого обучения компьютеры распознают, классифицируют и сопоставляют сложные закономерности во входных данных.
Этапы внедрения NLPКак правило, процесс NLP начинается со сбора и подготовки неструктурированных текстовых или речевых данных из таких источников, как облачные хранилища данных, опросы, электронные письма или внутренние приложения бизнес-процессов.
Программное обеспечение NLP использует методы предварительной обработки, такие как токенизация, стемминг, лемматизация и удаление стоп-слов, для подготовки данных для различных приложений.
- Токенизация разбивает предложение на отдельные единицы слов или фраз.
- Стемминг и лемматизация упрощают слова до их корневой формы. Например, эти процессы превращают начало в старт.
- Удаление стоп-слов гарантирует, что слова, которые не добавляют значимого смысла предложению, такие как для и с, будут удалены.
Исследователи используют предварительно обработанные данные для обучения моделей NLP с помощью машинного обучения для выполнения конкретных приложений на основе предоставленной текстовой информации. Обучение алгоритмов NLP требует предоставления программного обеспечения большими выборками данных для повышения их точности.
Затем специалисты по машинному обучению развертывают модель или интегрируют ее в существующую производственную среду. Модель NLP получает входные данные и прогнозирует выходные данные для конкретного сценария использования, для которого она предназначена. Приложение NLP можно запустить на живых данных и получить требуемый результат.
Что такое задачи NLP?
Методы NLP, или задачи NLP, разбивают человеческий текст или речь на более мелкие части, которые компьютерные программы могут легко понять. Общие возможности обработки и анализа текста в NLP приведены ниже.
Часть тегирования речиЭто процесс, при котором программное обеспечение NLP помечает отдельные слова в предложении в соответствии с контекстуальными обычаями, такими как существительные, глаголы, прилагательные или наречия. Это помогает компьютеру понять, как слова формируют значимые отношения друг с другом.
Некоторые слова могут иметь разные значения при использовании в разных сценариях. Например, слово «замок» в разных предложениях означает разные вещи.
- Замок – это средневековое строение.
- Люди используют замок, чтобы закрыть что-либо.
Устраняя неоднозначность смысла слов, программное обеспечение NLP определяет предполагаемое значение слова, обучая его языковую модель или ссылаясь на словарные определения.
Распознавание речи превращает голосовые данные в текст. Процесс включает в себя разбиение слов на более мелкие части и преодоление таких проблем, как акценты, оскорбления, интонация и неправильное использование грамматики в повседневном разговоре. Ключевым применением распознавания речи является транскрипция, которую можно выполнить с помощью сервисов преобразования речи в текст, таких как Amazon Transcribe.
Программное обеспечение для машинного перевода использует обработку естественного языка для преобразования текста или речи с одного языка на другой с сохранением контекстуальной точности. Сервис AWS, поддерживающий машинный перевод, – Amazon Translate.
Распознавание именованных сущностейЭтот процесс определяет уникальные имена людей, мест, событий, компаний и многого другого. Программное обеспечение NLP использует распознавание именованных сущностей для определения отношений между различными сущностями в предложении. Рассмотрим следующий пример.
Джейн отправилась во Францию на праздник и там побаловала себя местной кухней.
Программное обеспечение NLP выберет Джейн и Франция в качестве особых субъектов в предложении. Это может быть дополнительно расширено с помощью разрешения совместных ссылок, определяющего, используются ли разные слова для описания одного и того же субъекта. В приведенном выше примере и Джейн, и она указали на одного и того же человека.
В приведенном выше примере и Джейн, и она указали на одного и того же человека.
Анализ тональности – это основанный на искусственном интеллекте подход к интерпретации эмоций, передаваемых текстовыми данными. Программа NLP анализирует текст на наличие слов или фраз, которые показывают неудовлетворенность, счастье, сомнения, сожаление и другие скрытые эмоции.
Каковы подходы к обработке естественного языка?
Ниже мы приводим некоторые общие подходы к обработке естественного языка.
Контролируемая обработка естественного языка (NLP)Во время контролируемой обработки естественного языка программное обеспечение обучается с помощью набора маркированных или известных входов и выходов. Программа сначала обрабатывает большие объемы известных данных и учится получать правильные выходные данные из любого неизвестного ввода. Например, компании обучают инструменты NLP категоризации документов в соответствии с конкретными этикетками.
Неконтролируемая обработка естественного языка использует статистическую языковую модель для прогнозирования закономерности, которая возникает при подаче немаркированного ввода. Например, функция автозаполнения в текстовых сообщениях предлагает релевантные слова, которые имеют смысл для предложения, отслеживая ответ пользователя.
Понимание естественных языковПонимание естественного языка (NLU) – это подмножество NLP, которое фокусируется на анализе значения предложений. NLU позволяет программе находить похожие значения в разных предложениях или обрабатывать слова, которые имеют разные значения.
Генерация естественного языкаГенерация естественного языка (NLG) направлена на создание разговорного текста, как это делают люди, на основе определенных ключевых слов или тем. Например, интеллектуальный чат-бот с возможностями NLG может общаться с клиентами так же, как и сотрудники службы поддержки клиентов.
Как AWS может помочь в решении задач NLP?
AWS предоставляет самый широкий и полный набор сервисов искусственного интеллекта и машинного обучения для клиентов любого уровня знаний, связанных с полным набором источников данных.
Для клиентов, которым не хватает навыков машинного обучения, требуется более быстрый выход на рынок или которые хотят добавить интеллект к существующему процессу или приложению, AWS предлагает ряд языковых сервисов на основе машинного обучения, которые позволяют компаниям легко добавлять интеллектуальные данные в свои приложения искусственного интеллекта с помощью обученные API для речи, транскрипции, перевода, анализа текста и работы чат-бота. Сервисы включают Amazon Comprehend для поиска идей и связей в тексте, Amazon Transcribe для автоматического распознавания речи, Amazon Translate для свободного перевода текста, Amazon Polly для естественного звучания от текста к речи, Amazon Lex для создания чат-ботов для взаимодействия с клиентами и Amazon Kendra для интеллектуального поиска корпоративных систем для быстрого поиска нужного контента.
Для клиентов, которые хотят создать стандартное решение NLP в рамках своего бизнеса, Amazon SageMaker упрощает подготовку данных, создание, обучение и развертывание моделей машинного обучения для любого сценария использования с полностью управляемой инфраструктурой, инструментами и рабочими процессами, включая предложения без кода для бизнеса аналитики. С помощью Hugging Face на Amazon SageMaker вы можете развертывать и настраивать предварительно обученные модели от Hugging Face, поставщика моделей обработки естественного языка (NLP) с открытым исходным кодом, известного как Transformers, сокращая время настройки и использования этих моделей NLP с недель до минут.
Начните работу с обработкой естественного языка (NLP), создав аккаунт AWS уже сегодня.
Плавное введение в Natural Language Processing (NLP)
Введение в NLP с Sentiment Analysis в текстовых данных.Люди общаются с помощью каких-либо форм языка и пользуются либо текстом, либо речью. Сейчас для взаимодействия компьютеров с людьми, компьютерам необходимо понимать естественный язык, на котором говорят люди. Natural language processing занимается как раз тем, чтобы научить компьютеры понимать, обрабатывать и пользоваться естественными языками.
Natural language processing занимается как раз тем, чтобы научить компьютеры понимать, обрабатывать и пользоваться естественными языками.
В этой статье мы рассмотрим некоторые частые методики, применяющиеся в задачах NLP. И создадим простую модель сентимент-анализа на примере обзоров на фильмы, чтобы предсказать положительную или отрицательную оценку.
Что такое Natural Language Processing (NLP)?
NLP — одно из направлений искуственного интеллекта, которое работает с анализом, пониманем и генерацией живых языков, для того, чтобы взаимодействовать с компьютерами и устно, и письменно, используя естественные языки вместо компьютерных.
Применение NLP
- Machine translation (Google Translate)
- Natural language generation
- Поисковые системы
- Спам-фильтры
- Sentiment Analysis
- Чат-боты
… и так далее
Очистка данных (Data Cleaning):
При Data Cleaning мы удаляем из исходных данных особые знаки, символы, пунктуацию, тэги html <> и т. п., которые не содержат никакой полезной для модели информации и только добавляют шум в данные.
п., которые не содержат никакой полезной для модели информации и только добавляют шум в данные.
Что удалять из исходных данных, а что нет зависит от постановки задачи. Например, если вы работаете с текстом из сферы экономики или бизнеса, знаки типа $ или другие символы валют могут содержать скрытую информацию, которую вы не хотите потерять. Но в большинстве случаев, мы их удаляем.
Код на Python: Data cleaning
Предварительная обработка данных (Preprocessing of Data)
Preprocessing of Data это этап Data Mining, который включает в себя трансформацию исходных данных в доступный для понимания формат.
Изменение регистра:
Одна из простейших форм предварительной обработки текста — перевод всех символов текста в нижний регистр.
Источник изображения
Код на Python: перевод в нижний регистр
Токенизация:
Токенизация — процесс разбиения текстового документа на отдельные слова, которые называются токенами.
Код на Python: Токенизация
Как можно видеть выше, предложение разбито на слова (токены).
Natural language toolkit (библиотека NLTK) — популярный открытый пакет библиотек, используемых для разного рода задач NLP. В этой статье мы будем использовать библиотеку NLTK для всех этапов Text Preprocessing.
Вы можете скачать библиотеку NLTK с помощью pip:
!pip install nltk
Удаление стоп-слов:
Стоп-слова — это часто используемые слова, которые не вносят никакой дополнительной информации в текст. Слова типа «the», «is», «a» не несут никакой ценности и только добавляют шум в данные.
В билиотеке NLTK есть встроенный список стоп-слов, который можно использовать, чтобы удалить стоп-слова из текста. Однако это не универсальный список стоп-слов для любой задачи, мы также можем создать свой собствпнный набор стоп-слов в зависимости от сферы.
Код на Python: Удаление стоп-слов
В библиотеке NLTK есть заранее заданный список стоп-слов. Мы можем добавитьили удалить стоп-слова из этого списка или использовать его в зависимости от конкретной задачи.
Мы можем добавитьили удалить стоп-слова из этого списка или использовать его в зависимости от конкретной задачи.
Стеммизация:
Стеммизация — процесс приведения слова к его корню/основе.
Он приводит различные вариации слова (например, «help», «helping», «helped», «helpful») к его начальной форме (например, «help»), удаляет все придатки слов (приставка, суффикс, окончание) и оставляет только основу слова.
Источник изображения
Код на Python: Стеммизация
Корень слова может быть существующим в языке словом, а может и не быть им. Например, «mov» корень слова «movie», «emot» корень слова «emotion».
Лемматизация:
Лемматизация похожа на стеммизацию в том, что она приводит слово к его начальной форме, но с одним отличием: в данном случае корень слова будет существующим в языке словом. Например, слово «caring» прекратится в «care», а не «car», как в стеммизаци.
Код на Python: Лемматизация
WordNet — это база существующих в английском языке слов. Лемматизатор из NLTK WordNetLemmatizer() использует слова из WordNet.
Лемматизатор из NLTK WordNetLemmatizer() использует слова из WordNet.
N-граммы:
Источник изображения
N-граммы — это комбинации из нескольких слов, использующихся вместе, N-граммы, где N=1 называются униграммами (unigrams). Подобным же образом, биграммы (N=2), триграммы (N=3) и дальше можно продолдать аналогичным способом.
N-граммы могут использоваться, когда нам нужно сохранить какую-то последовательность данных, например, какое слово чаще следует за заданным словом. Униграммы не содержат никкой последовательности данных, так как каждое слово берется индивидуально.
Векторизация текстовых данных (Text Data Vectorization):
Процесс конвертации текста в числа называется векторизацией. Теперь после Text Preprocessing, нам нужно представить текст в числовом виде, то есть закодировать текстовые данные в виде чисел, которые в дальнейшем могут использоваться в алгоритмах.
«Мешок слов» (Bag of words (BOW)):
Это одна из самых простых методик векторизации текста. В логике BOW два предложения могут называться одинаковыми, если содержат один и тот же набор слов.
В логике BOW два предложения могут называться одинаковыми, если содержат один и тот же набор слов.
Рассмотрим два предложения:
Источник изображения
В задачах NLP, каждое текстовое предложение называется документом, а несколько таких документов называют корпусом текстов.
BOW создает словарь уникальных d слов в корпусе (собрание всех токенов в данных). Например, корпус на изображении выше состоит из всех слов предложений S1 и S2.
Теперь мы можем создать таблицу, где столбцы соответствуют входящим в корпус уникальным d словам, а строки предложениям (документам). Мы устанавливаем значение 1, если слово в предложении есть, и 0, если его там нет.
Источник изображения
Это позволит создать dxn матрицу, где d это общее число уникальных токенов в корпусе и n равно числу документов. В примере выше матрица будет иметь форму 11×2.
TF-IDF:
Источник изображения
Это расшифровывается как Term Frequency (TF)-Inverse Document Frequency (IDF).
Частота слова (Term Frequency):
Term Frequency высчитывает вероятность найти какое-то слово в документе. Ну, например, мы хотим узнать, какова вероятрность найти слово wi в документе dj.
Term Frequency (wi, dj) =
Количество раз, которое wi встречается в dj / Общее число слов в dj
Обратная частота документа (Inverse Document Frequency):
В логике IDF, если слово встречается во всех документах, оно не очень полезно. Так определяется, насколько уникально слово во всем корпусе.
IDF(wi, Dc) = log(N/ni)
Здесь Dc = Все документы в корпусе,
N = Общее число документов,
ni = документы, которые содержат слово (wi).
Если wi встречается в корпусе часто, значение IDF снижается.
Если wi используется не часто, то ni снижается и вследствие этого значение IDF возрастает.
TF(wi, dj) * IDF(wi, Dc)
TF-IDF — умножение значений TF и IDF. Больший вес получат слова, которые встречаются в документе чаще, чем во всем остальном корпусе.
Sentiment Analysis: Обзоры фильмов на IMDb
Источник изображения
Краткая информация
Набор данных содержит коллекцию из 50 000 рецензий на сайте IMDb, с равным количеством положительных и отрицательных рецензий. Задача — предсказать полярность (положительную или отрицательную) данных отзывов (тексты).
1. Загрузка и исследование данных
Набор данных IMDB можно скачать здесь.
Обзор набора данных:Положительные рецензии отмечены 1, а отрицательные 0.
Пример положительной рецензии:Пример отрицательной рецензии:
2. Data Preprocessing
На этом этапе мы совершаем все шаги очистки и предварительной обработки данных тем методом, который был описан выше. Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
Мы используем лемматизацию, а не стеммизацию, потому что в процессе тестирования результатов обоих случаев лемматизация дает лучшие результаты, чем стеммизация.
Использовать ли стеммизацию или лемматизацию или и то, и другое — зависит от поставленной задачи, так что нам стоит попробовать и решить, какой способ сработает лучше для данной задачи.
Добавляем новую колонку preprocessed_review в dataframe, применяя data_preprocessing() ко всем рецензиям.
3. Vectorizing Text (рецензии)
Разделяем набор данных на train и test (70–30):Используем train_test_split из sklearn, чтобы разделить данные на train и test. Здесь используем параметр stratify,чтобы иметь равную пропорцию классов в train и test.
BOWЗдесь мы использовали min_df=10, так как нам нужны были только те слова, которые появляются как минимум 10 раз во всем корпусе.
TF-IDF4.
 Создание классификаторов MLНаивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными BOW
Создание классификаторов MLНаивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными BOWNaive Bayes c BOW выдает точность 84.6%. Попробуем с TF-IDF.
Наивный байесовский классификатор (Naive Bayes) с рецензиями, закодированными TF-IDF
TF-IDF выдает результат немного лучше (85.3%), чем BOW. Теперь давайте попробуем TF-IDF с простой линеарной моделью, Logistic Regression.
Logistic Regression с рецензиями, закодированными TF-IDF
Logistic Regression с рецензиями, закодированными TF-IDF, выдает результат лучше, чем наивный байемовский — точность 88.0%.
Построение матрицы неточностей даст нам информацию о том, сколько точек данных верны и сколько неверны, классифицированную с помощью модели.
Из 7500 отрицательных рецензий 6515 были верно классифицированы как отрицательные и 985 были неверно классифицированы как положительные. Из 7500 положительных рацензий 6696 были верно классифицированы как положительные, и 804 неверно классифицированы как отрицательные.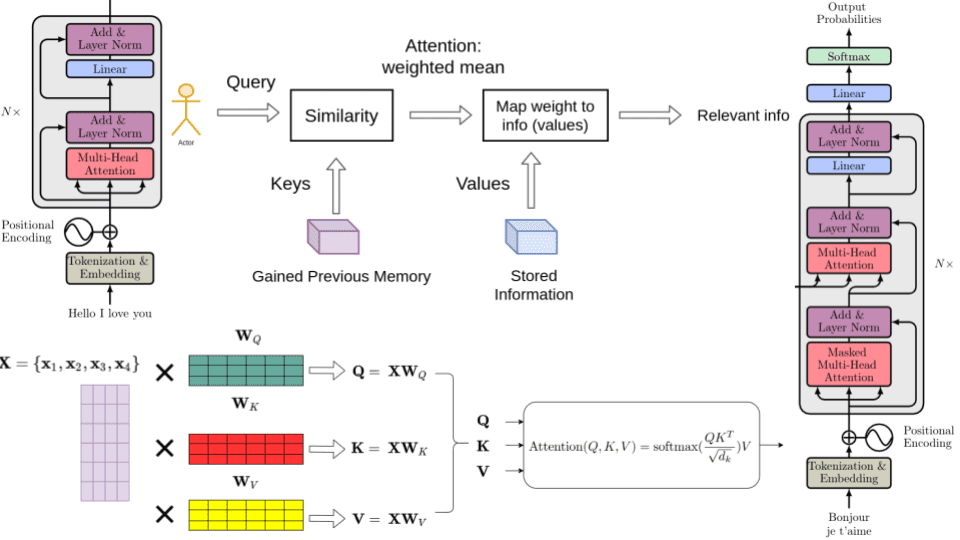
Итоги
Мы узнали основные задачи NLP и создали простые модели ML для сентимент-анализа рецензий на фильмы. В дальнейшем усоверешенствований можно добиться с помощью Word Embedding с моделями Deep Learning.
Благодарю за внимание! Полный код смотрите здесь.
Ссылки:
- Ultimate guide to deal with Text Data (using Python) – for Data Scientists and Engineers
- All you need to know about text preprocessing for NLP and Machine Learning
- Applied Course
Источник
Обработка естественного языка (NLP) для машинного обучения
Обработка естественного языка (NLP) является частью повседневной жизни и имеет важное значение для нашей жизни дома и на работе. Не задумываясь, мы отправляем голосовые команды нашим виртуальным домашним помощникам, нашим смартфонам и даже нашим автомобилям. Приложения с поддержкой голоса, такие как Alexa, Siri и Google Assistant, используют NLP и машинное обучение (ML), чтобы отвечать на наши вопросы, добавлять действия в наши календари и звонить контактам, которые мы указываем в наших голосовых командах. НЛП не только облегчает нашу жизнь, но и меняет то, как мы работаем, живем и играем.
НЛП не только облегчает нашу жизнь, но и меняет то, как мы работаем, живем и играем.
Работайте с нами! Давай поговорим!
Различия между обработкой естественного языка и машинным обучением
Хотя обработка естественного языка, машинное обучение и искусственный интеллект иногда используются взаимозаменяемо, они имеют разные определения. ИИ — это общий термин для машин, которые могут имитировать человеческий интеллект, в то время как НЛП и машинное обучение являются подмножествами ИИ.
Искусственный интеллект является частью более широкой области компьютерных наук, которая позволяет компьютерам решать проблемы, ранее решаемые биологическими системами. ИИ имеет множество применений в современном обществе. НЛП и машинное обучение являются частями ИИ.
Обработка естественного языка — это форма ИИ, которая дает машинам возможность не только читать, но и понимать и интерпретировать человеческий язык. С помощью НЛП машины могут понимать письменный или устный текст и выполнять задачи, включая распознавание речи, анализ настроений и автоматическое суммирование текста.
Машинное обучение — это приложение ИИ, которое предоставляет системам возможность автоматически учиться и совершенствоваться на основе опыта без явного программирования. Машинное обучение можно использовать для решения проблем с ИИ и улучшения NLP за счет автоматизации процессов и предоставления точных ответов.
Как видно из рисунка 1, NLP и ML являются частью ИИ, и оба подмножества используют общие методы, алгоритмы и знания.
Как можно применять обработку естественного языка
Некоторые решения на основе НЛП включают перевод, распознавание речи, анализ настроений, системы вопросов и ответов, чат-боты, автоматическое суммирование текста, анализ рынка, автоматическую классификацию текста и автоматическую проверку грамматики. Эти технологии помогают организациям анализировать данные, получать информацию, автоматизировать трудоемкие процессы и/или получать конкурентные преимущества.
Перевод
Перевод языков является более сложным, чем простой метод замены слов. Поскольку в каждом языке есть правила грамматики, задача перевода текста состоит в том, чтобы сделать это без изменения его смысла и стиля. Поскольку компьютеры не понимают грамматики, им нужен процесс, в котором они могут деконструировать предложение, а затем реконструировать его на другом языке так, чтобы это имело смысл.
Поскольку в каждом языке есть правила грамматики, задача перевода текста состоит в том, чтобы сделать это без изменения его смысла и стиля. Поскольку компьютеры не понимают грамматики, им нужен процесс, в котором они могут деконструировать предложение, а затем реконструировать его на другом языке так, чтобы это имело смысл.
Google Translate — один из самых известных онлайн-переводчиков. Google Translate когда-то использовал машинный перевод на основе фраз (PBMT), который ищет похожие фразы между разными языками. В настоящее время Google вместо этого использует Google Neural Machine Translation (GNMT), который использует ML с NLP для поиска шаблонов в языках.
Распознавание речи
Распознавание речи — это способность машины идентифицировать и интерпретировать фразы и слова из устной речи и преобразовывать их в машиночитаемый формат. Он использует NLP, чтобы позволить компьютерам имитировать человеческое взаимодействие, и ML, чтобы реагировать таким образом, который имитирует человеческие реакции.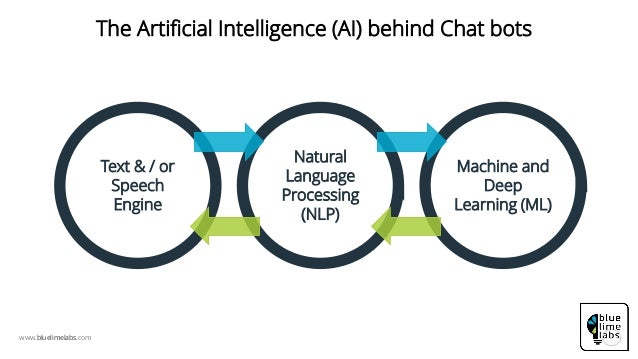
Google Now, Alexa и Siri — одни из самых популярных примеров распознавания речи. Просто сказав «позвонить Джейн», мобильное устройство распознает, что означает эта команда, и теперь позвонит контакту, сохраненному как Джейн.
Анализ настроений
Анализ настроений использует НЛП и машинное обучение для интерпретации и анализа эмоций в субъективных данных, таких как новостные статьи и твиты. Можно определить положительные, отрицательные и нейтральные мнения, чтобы определить отношение клиента к бренду, продукту или услуге. Анализ настроений используется для оценки общественного мнения, отслеживания репутации бренда и лучшего понимания опыта клиентов.
Фондовый рынок — чувствительная сфера, на которую могут сильно влиять человеческие эмоции. Негативные настроения могут привести к падению цен на акции, в то время как положительные настроения могут побудить людей покупать больше акций компании, что приведет к росту цен на акции.
Чат-боты
Чат-боты — это программы, используемые для предоставления автоматических ответов на распространенные запросы клиентов. У них есть системы распознавания образов с эвристическими ответами, которые используются для общения с людьми. Первоначально чат-боты использовались для ответов на основные вопросы, чтобы облегчить работу колл-центров с большим объемом звонков и предложить услуги быстрой поддержки клиентов.
У них есть системы распознавания образов с эвристическими ответами, которые используются для общения с людьми. Первоначально чат-боты использовались для ответов на основные вопросы, чтобы облегчить работу колл-центров с большим объемом звонков и предложить услуги быстрой поддержки клиентов.
Но чат-боты с искусственным интеллектом предназначены для обработки более сложных запросов, что делает общение более интуитивным. Чат-боты в здравоохранении, например, могут собирать данные о приеме, помогать пациентам оценивать свои симптомы и определять следующие шаги. Эти чат-боты могут назначать встречи с нужным врачом и даже рекомендовать лечение.
Системы вопросов и ответов
Системы вопросов и ответов представляют собой интеллектуальные системы, которые используются для предоставления ответов на запросы клиентов. Помимо чат-ботов, системы вопросов и ответов обладают огромным набором знаний и хорошим пониманием языка, а не готовыми ответами. Они могут ответить на такие вопросы, как «Когда был убит Авраам Линкольн?» или «Как добраться до аэропорта?» и может быть создан для работы с текстовыми данными, аудио, изображениями и видео.
Системы вопросов и ответов можно найти в чатах социальных сетей и таких инструментах, как Siri и IBM Watson. В 2011 году компьютер IBM Watson участвовал в игровом шоу Jeopardy, во время которого сначала даются ответы, а участники задают вопросы. Компьютер конкурировал с двумя крупнейшими чемпионами всех времен и поразил технологическую индустрию, заняв первое место.
Автоматическое суммирование текста
Автоматическое суммирование текста — это задача сокращения фрагмента текста до более короткой версии путем извлечения его основных идей и сохранения смысла содержания. Это приложение NLP используется в заголовках новостей, фрагментах результатов веб-поиска и бюллетенях рыночных отчетов.
Анализ рынка
Анализ рынка — это сбор ценной информации о тенденциях, потребителях, продуктах и конкурентах для извлечения полезной информации, которую можно использовать для принятия стратегических решений. Market Intelligence может анализировать темы, настроения, ключевые слова и намерения в неструктурированных данных и требует меньше времени, чем традиционные кабинетные исследования.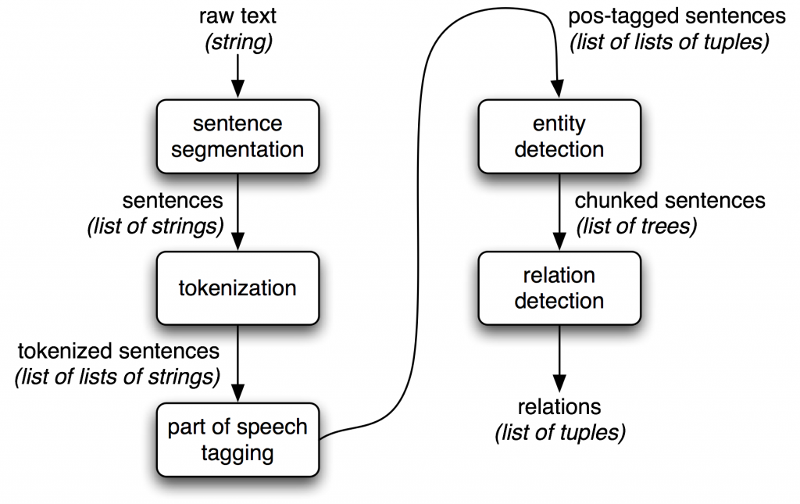
Используя Market Intelligence, организации могут отслеживать поисковые запросы и добавлять контекстуально релевантные синонимы к результатам поиска. Это также может помочь организациям решить, какие продукты или услуги следует прекратить или на каких клиентов ориентироваться.
Автоматическая классификация текста
Автоматическая классификация текста — еще одно фундаментальное решение НЛП. Это процесс присвоения тегов тексту в соответствии с его содержанием и семантикой, что позволяет быстро и легко извлекать информацию на этапе поиска. Это приложение НЛП может отличать спам от не-спама на основе его содержимого.
Автоматическая проверка грамматики
Автоматическая проверка грамматики, задача обнаружения и исправления грамматических и орфографических ошибок в тексте в зависимости от контекста, является еще одной важной частью НЛП. Автоматическая проверка грамматики предупредит вас о возможной ошибке, подчеркнув слово красным цветом.
Преимущества и недостатки обработки естественного языка
Как и многие другие формы искусственного интеллекта, использование обработки естественного языка имеет как преимущества, так и недостатки.
Преимущества НЛП включают:
- После внедрения НЛП становится менее дорогим и более эффективным по времени, чем наем человека.
- НЛП также может помочь предприятиям предложить более быстрое время отклика службы поддержки клиентов . Независимо от времени суток или дня недели клиенты получают немедленные ответы на свои вопросы.
- Предварительно обученные модели машинного обучения широко доступны для разработчиков, чтобы упростить различные приложения NLP, что делает их легко реализовать .
Достижения НЛП многообещающи, но у НЛП есть и некоторые недостатки.
К недостаткам НЛП относятся:
- Обучение может занимать много времени. Если необходимо разработать новую модель без использования предварительно обученной модели, могут пройти недели, прежде чем будет достигнут высокий уровень производительности.
- Другим недостатком НЛП является то, что машинное обучение не является на 100% надежным .
 Всегда существует вероятность ошибок в прогнозах и результатах, которые необходимо учитывать.
Всегда существует вероятность ошибок в прогнозах и результатах, которые необходимо учитывать.
 Всегда существует вероятность ошибок в прогнозах и результатах, которые необходимо учитывать.
Всегда существует вероятность ошибок в прогнозах и результатах, которые необходимо учитывать.Добавление NLP и ML в ваш продукт
Основная причина добавления обработки естественного языка и машинного обучения в ваш программный продукт — это получение конкурентного преимущества. С помощью чат-ботов ваши пользователи могут круглосуточно и без выходных получать немедленный ответ на запросы в службу поддержки клиентов.
Скорость, с которой можно выполнить оценку рисков с помощью алгоритмов машинного обучения, может повысить ценность вашего предприятия.
Чтобы узнать больше, обратитесь к эксперту Encora.
Заключение
Обработка естественного языка — это практика обучения машин понимать и интерпретировать разговорные данные людей. НЛП на основе машинного обучения можно использовать для установления каналов связи между людьми и машинами. Несмотря на постоянное развитие, НЛП уже доказало свою полезность во многих областях. Различные реализации NLP могут помочь предприятиям и частным лицам сэкономить время, повысить эффективность и повысить удовлетворенность клиентов.
Еда на вынос
- Обработка естественного языка (NLP) — это форма искусственного интеллекта, которая дает машинам возможность читать и интерпретировать человеческий язык. С помощью НЛП машины могут понимать письменный или устный текст.
- НЛП постоянно развивается, но существующие решения на основе НЛП включают в себя перевод, распознавание речи, анализ настроений, системы вопросов и ответов, автоматическое суммирование текста, чат-боты, анализ рынка, автоматическую классификацию текста и автоматическую проверку грамматики.
- Использование обработки естественного языка имеет как преимущества, так и недостатки. Предприятия могут сократить расходы, сократить время ожидания клиентов и повысить удовлетворенность клиентов при внедрении НЛП. Но обучение может занять время, а машинное обучение никогда не бывает на 100% надежным.
Звоните по номеру , свяжитесь с нами по номеру , чтобы узнать больше о том, как НЛП может помочь развитию вашего бизнеса.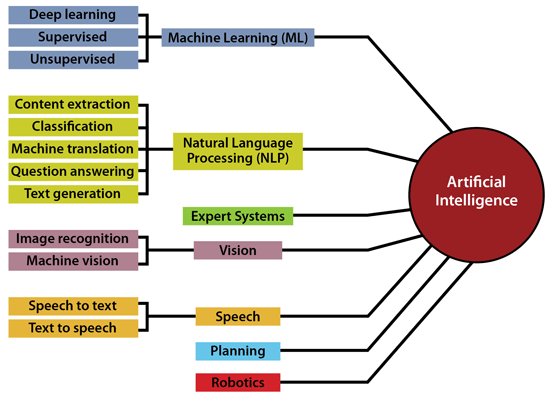
О компании Encora
Encora ускоряет получение бизнес-результатов для клиентов с помощью передовых инновационных цифровых продуктов. Мы предоставляем инновационные услуги и программные инженерные решения для широкого спектра передовых технологий, включая большие данные, аналитику, машинное обучение, Интернет вещей, мобильные устройства, облачные технологии, UI/UX и автоматизацию тестирования. Нажмите здесь , чтобы узнать больше о наших услугах. Давайте обсудим, как мы можем помочь вашему бизнесу.
НЛП, машинное обучение и искусственный интеллект, объяснение
Компании все чаще используют инструменты, оснащенные НЛП, для анализа данных и автоматизации рутинных задач.
Обработка естественного языка (NLP) — это ветвь искусственного интеллекта (ИИ), позволяющая машинам понимать человеческий язык. Его цель — создать системы, которые могут понимать текст и автоматически выполнять такие задачи, как перевод, проверка орфографии или классификация тем.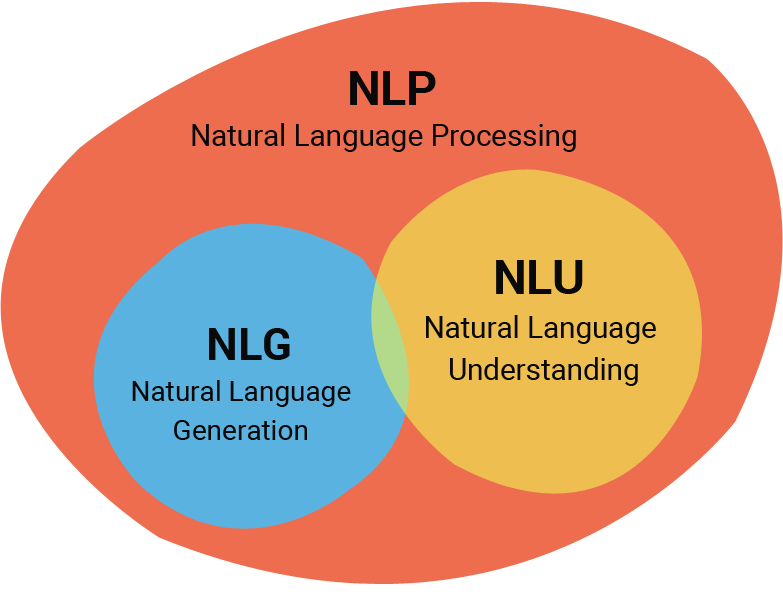
Автоматизируйте рутинные задачи с помощью НЛП
ПОПРОБУЙТЕ СЕЙЧАС
Но что такое обработка естественного языка? Чем он отличается от других родственных терминов, таких как ИИ и машинное обучение?
- Что такое обработка естественного языка (NLP)?
- НЛП, ИИ, машинное обучение: в чем разница?
- Методы НЛП
- 5 вариантов использования НЛП в бизнесе
Что такое обработка естественного языка?
Обработка естественного языка (NLP) позволяет компьютерам понимать человеческий язык. За кулисами НЛП анализирует грамматическую структуру предложений и индивидуальное значение слов, а затем использует алгоритмы для извлечения значения и предоставления результатов. Другими словами, он осмысливает человеческий язык, чтобы автоматически выполнять различные задачи.
Вероятно, наиболее популярными примерами NLP в действии являются виртуальные помощники, такие как Google Assist, Siri и Alexa. НЛП понимает письменный и устный текст, например «Эй, Сири, где ближайшая заправка?» и преобразует его в числа, облегчая понимание машинами.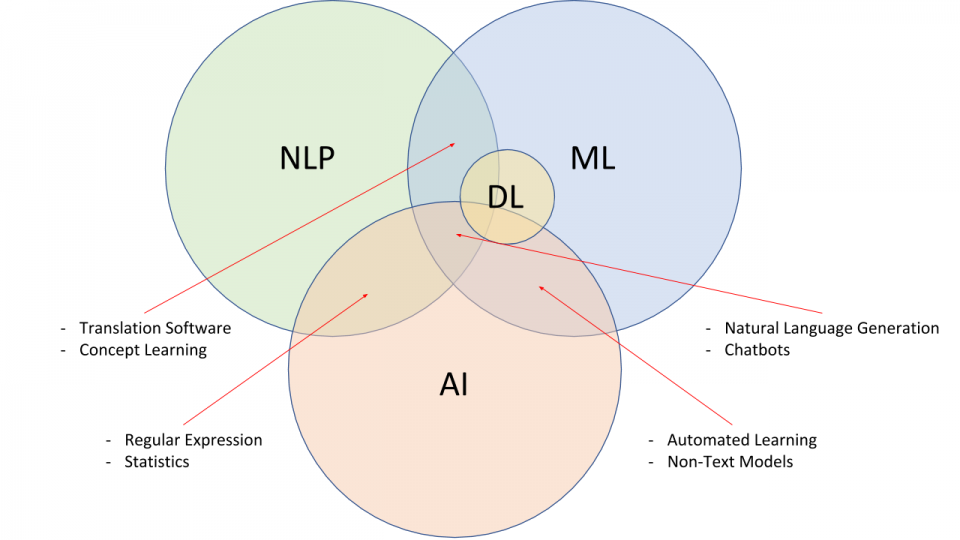
Еще одно известное применение НЛП — чат-боты. Они помогают группам поддержки решать проблемы, понимая запросы на общем языке и отвечая автоматически.
Есть много других повседневных приложений, в которых вы, вероятно, столкнулись с НЛП, даже не заметив этого. Текстовые рекомендации при написании электронного письма, предложение перевести сообщение Facebook, написанное на другом языке, или фильтрация нежелательных рекламных писем в папку со спамом.
В двух словах, цель обработки естественного языка — сделать человеческий язык — сложный, неоднозначный и чрезвычайно разнообразный — простым для понимания машинами.
НЛП, ИИ, машинное обучение: в чем разница?
Обработка естественного языка (NLP), искусственный интеллект (AI) и машинное обучение (ML) иногда используются взаимозаменяемо, поэтому вы можете спутать провода, пытаясь провести различие между ними.
Первое, что нужно знать, это то, что НЛП и машинное обучение являются подмножествами искусственного интеллекта.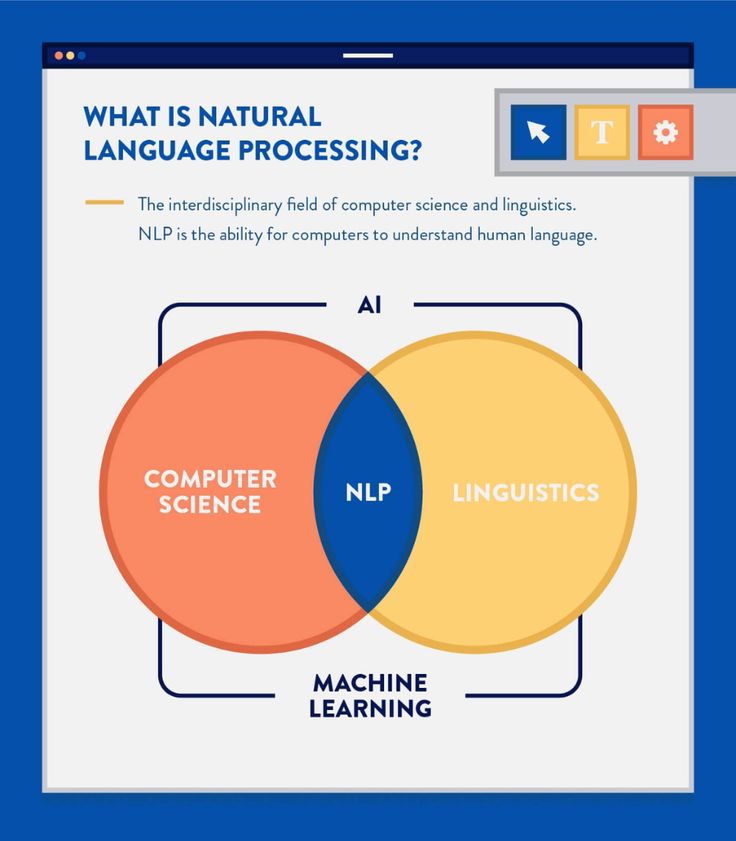
ИИ — это общий термин для машин, которые могут имитировать человеческий интеллект. ИИ включает в себя системы, которые имитируют когнитивные способности, такие как обучение на примерах и решение проблем. Это охватывает широкий спектр приложений, от беспилотных автомобилей до систем прогнозирования.
Обработка естественного языка (NLP) связана с тем, как компьютеры понимают и переводят человеческий язык. С помощью НЛП машины могут понимать письменный или устный текст и выполнять такие задачи, как перевод, извлечение ключевых слов, классификация тем и многое другое.
Но для автоматизации этих процессов и предоставления точных ответов вам потребуется машинное обучение. Машинное обучение — это процесс применения алгоритмов, которые учат машины автоматически учиться и совершенствоваться на основе опыта без явного программирования.
Чат-боты на основе ИИ, например, используют НЛП для интерпретации того, что говорят пользователи и что они намерены делать, и машинное обучение для автоматического предоставления более точных ответов на основе прошлых взаимодействий.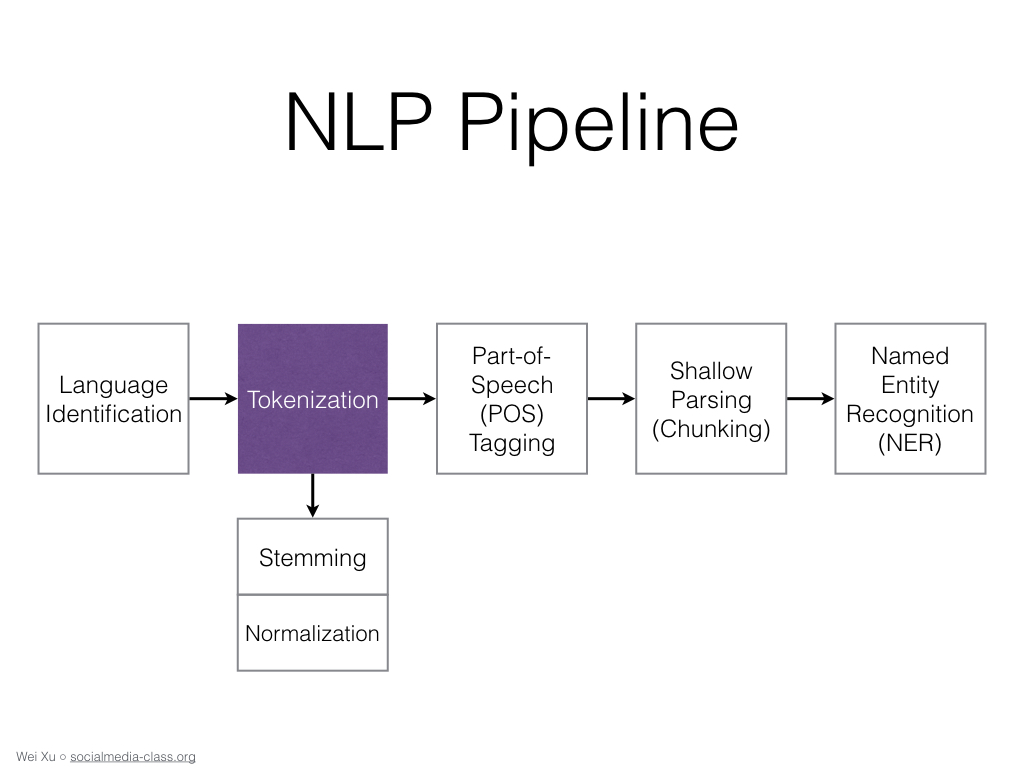
Техники НЛП
Обработка естественного языка (NLP) применяет два метода, помогающих компьютерам понимать текст: синтаксический анализ и семантический анализ.
Синтаксический анализ
Синтаксический анализ ‒ или синтаксический анализ ‒ анализирует текст с использованием основных грамматических правил для определения структуры предложения, того, как слова организованы и как слова соотносятся друг с другом.
Некоторые из его основных подзадач включают:
- Токенизация состоит из разбиения текста на более мелкие части, называемые токены (которые могут быть предложениями или словами), чтобы облегчить работу с текстом.
- Тегирование части речи (тегирование PoS) помечает токены как глагол, наречие, прилагательное, существительное и т. д. Это помогает сделать вывод о значении слова (например, слово «книга» означает разные вещи, если используется как глагол или существительное).
- Лемматизация и формирование корней состоят из приведения флективных слов к их основной форме, чтобы их было легче анализировать.
- Удаление стоп-слов удаляет часто встречающиеся слова, не добавляющие семантической ценности, такие как I, they, have, like, yours и т. д. текста. Во-первых, изучает значение каждого отдельного слова (лексическая семантика). Затем он смотрит на комбинацию слов и то, что они означают в контексте. Основными подзадачами семантического анализа являются:
- Устранение неоднозначности смысла слова пытается определить, в каком смысле слово используется в данном контексте.
- Извлечение отношений пытается понять, как объекты (места, люди, организации и т. д.) связаны друг с другом в тексте.
5 Примеры использования НЛП в бизнесе
Инструменты НЛП помогают компаниям понять, как их клиенты воспринимают их по всем каналам связи, будь то электронная почта, обзоры продуктов, сообщения в социальных сетях, опросы и многое другое.
Инструменты искусственного интеллекта можно использовать не только для понимания онлайн-разговоров и того, как клиенты говорят о компаниях, но и для автоматизации повторяющихся и трудоемких задач, повышения эффективности и предоставления работникам возможности сосредоточиться на более важных задачах.
Вот некоторые из основных применений НЛП в бизнесе:
Анализ настроений
Анализ настроений идентифицирует эмоции в тексте и классифицирует мнения как положительные, отрицательные или нейтральные. Вы можете увидеть, как это работает, вставив текст в этот бесплатный инструмент анализа настроений.
Анализируя сообщения в социальных сетях, обзоры продуктов или онлайн-опросы, компании могут получить представление о том, как клиенты относятся к брендам или продуктам. Например, вы можете анализировать твиты, в которых упоминается ваш бренд, в режиме реального времени и сразу обнаруживать комментарии от разгневанных клиентов.
Может быть, вы хотите разослать опрос, чтобы узнать, что клиенты думают о вашем уровне обслуживания клиентов.
Анализируя открытые ответы на опросы NPS, вы можете определить, какие аспекты вашего обслуживания клиентов получают положительные или отрицательные отзывы.Языковой перевод
За последние несколько лет технология машинного перевода значительно улучшилась, и в 2019 году переводы Facebook достигли сверхчеловеческой производительности. рынки.
Вы также можете обучить инструменты перевода понимать специфическую терминологию в любой отрасли, например, в финансах или медицине. Таким образом, вам не нужно беспокоиться о неточном переводе, который характерен для стандартных инструментов перевода.
Извлечение текста
Извлечение текста позволяет извлекать заранее определенную информацию из текста. Если вы имеете дело с большими объемами данных, этот инструмент поможет вам распознавать и извлекать релевантные ключевые слова и функции (например, коды продуктов, цвета и характеристики), а также именованные объекты (например, имена людей, местоположения, названия компаний, электронные письма и т.
д.).Компании могут использовать извлечение текста для автоматического поиска ключевых терминов в юридических документах, определения основных слов, упомянутых в заявках на поддержку клиентов, или извлечения спецификаций продукта из абзаца текста, а также во многих других приложениях. Звучит интересно? Вот инструмент для извлечения ключевых слов, который вы можете попробовать.
Чат-боты
Чат-боты — это системы искусственного интеллекта, предназначенные для взаимодействия с людьми посредством текста или речи.
Использование чат-ботов для обслуживания клиентов растет из-за их способности предлагать помощь 24/7 (сокращая время ответа), обрабатывать несколько запросов одновременно и освобождать агентов от ответов на повторяющиеся вопросы.
Чат-боты активно учатся при каждом взаимодействии и лучше понимают намерения пользователей, поэтому вы можете положиться на них при выполнении повторяющихся и простых задач. Если они сталкиваются с запросом клиента, на который не могут ответить, они передают его агенту-человеку.
Классификация тем
Классификация тем помогает организовать неструктурированный текст по категориям. Для компаний это отличный способ получить представление о отзывах клиентов.
Представьте, что вы хотите проанализировать сотни открытых ответов на опросы NPS. Сколько ответов упоминают вашу службу поддержки? О каком проценте клиентов говорят «Цены» ? С помощью этого классификатора тем для отзывов о NPS все ваши данные будут помечены за считанные секунды.
Кроме того, вы можете использовать классификацию тем, чтобы автоматизировать процесс пометки входящих заявок в службу поддержки и автоматически направлять их нужному человеку.
Закрытие
Обработка естественного языка (NLP) — это часть ИИ, которая изучает, как машины взаимодействуют с человеческим языком. NLP работает за кулисами, чтобы улучшить инструменты, которые мы используем каждый день, такие как чат-боты, средства проверки орфографии или языковые переводчики.
В сочетании с алгоритмами машинного обучения НЛП создает системы, которые учатся выполнять задачи самостоятельно и становятся лучше с опытом.

 Анализируя открытые ответы на опросы NPS, вы можете определить, какие аспекты вашего обслуживания клиентов получают положительные или отрицательные отзывы.
Анализируя открытые ответы на опросы NPS, вы можете определить, какие аспекты вашего обслуживания клиентов получают положительные или отрицательные отзывы. д.).
д.).