пошаговое руководство по обработке естественного языка / Хабр
Неважно, кто вы — зарекомендовавшая себя компания, или же только собираетесь запустить свой первый сервис — вы всегда можете использовать текстовые данные для того, чтобы проверить ваш продукт, усовершенствовать его и расширить его функциональность.
Обработкой естественного языка (NLP) называется активно развивающаяся научная дисциплина, занимающаяся поиском смысла и обучением на основании текстовых данных.
Как вам может помочь эта статья
За прошедший год команда Insight приняла участие в работе над несколькими сотнями проектов, объединив знания и опыт ведущих компаний в США. Результаты этой работы они обобщили в статье, перевод которой сейчас перед вами, и вывели подходы к решению наиболее распространенных прикладных задач машинного обучения.
Мы начнем с самого простого метода, который может сработать — и постепенно перейдем к более тонким подходам, таким как feature engineering, векторам слов и глубокому обучению.
После прочтения статьи, вы будете знать, как:
- осуществлять сбор, подготовку, и инспектирование данных;
- строить простые модели, и осуществлять при необходимости переход к глубокому обучению;
- интерпретировать и понимать ваши модели, чтобы убедиться, что вы интерпретируете информацию, а не шум.
Пост написан в формате пошагового руководства; также его можно рассматривать в качестве обзора высокоэффективных стандартных подходов.
К оригинальному посту прилагается интерактивный блокнот Jupyter, демонстрирующий применение всех упомянутых техник. Мы призываем вас воспользоваться им по мере того, как вы будете читать статью.
Применение машинного обучения для понимания и использования текста
Обработка естественного языка позволяет получать новыевосхитительныерезультаты и является очень широкой областью. Однако, Insight идентифицировала следующие ключевые аспекты практического применения, которые встречаются гораздо чаще остальных:
- Идентификация различных когорт пользователей или клиентов (например, предсказание оттока клиентов, совокупной прибыли клиента, продуктовых предпочтений)
- Точное детектирование и извлечение различных категорий отзывов (позитивные и негативные мнения, упоминания отдельных атрибутов вроде размера одежды и т.
 д.)
д.) - Классификация текста в соответствии с его смыслом (запрос элементарной помощи, срочная проблема).
 д.)
д.)Невзирая на наличие большого количества научных публикаций и обучающих руководств на тему NLP в интернете, на сегодняшний день практически не существует полноценных рекомендаций и советов на тему того, как эффективно справляться с задачами NLP, при этом рассматривающих решения этих задач с самых основ.
Шаг 1: Соберите ваши данные
Примерные источники данных
Любая задача машинного обучения начинается с данных — будь то список адресов электронной почты, постов или твитов. Распространенными источниками текстовой информации являются:
- Отзывы о товарах (Amazon, Yelp и различные магазины приложений).
- Контент, созданный пользователями (твиты, посты в Facebook, вопросы на StackOverflow).
- Диагностическая информация (запросы пользователей, тикеты в поддержку, логи чатов).
Датасет «Катастрофы в социальных медиа»
Для иллюстрации описываемых подходов мы будем использовать датасет «Катастрофы в социальных медиа», любезно предоставленный компанией CrowdFlower.
Авторы рассмотрели свыше 10 000 твитов, которые были отобраны при помощи различных поисковых запросов вроде «в огне», «карантин» и «столпотворение». Затем они пометили, имеет ли твит отношение к событию-катастрофе (в отличие от шуток с использованием этих слов, обзоров на фильмы или чего-либо, не имеющего отношение к катастрофам).
Поставим себе задачу определить, какие из твитов имеют отношение к событию-катастрофе в противоположность тем твитам, которые относятся к нерелевантным темам
(например, фильмам). Зачем нам это делать? Потенциальным применением могло бы быть эксклюзивное уведомление должностных лиц о чрезвычайных ситуациях, требующих неотложного внимания — при этом были бы проигнорированы обзоры последнего фильма Адама Сэндлера. Особая сложность данной задачи заключается в том, что оба этих класса содержат одни и те же критерии поиска, поэтому нам придется использовать более тонкие отличия, чтобы разделить их.
Особая сложность данной задачи заключается в том, что оба этих класса содержат одни и те же критерии поиска, поэтому нам придется использовать более тонкие отличия, чтобы разделить их.Далее мы будем ссылаться на твиты о катастрофах как «катастрофа», а на твиты обо всём остальном как «нерелевантные».
Метки (Labels)
Наши данные имеют метки, так что мы знаем, к каким категориям принадлежат твиты. Как подчеркивает Ричард Сочер, обычно быстрее, проще и дешевле найти и разметить достаточно данных, на которых будет обучаться модель — вместо того, чтобы пытаться оптимизировать сложный метод обучения без учителя.
Rather than spending a month figuring out an unsupervised machine learning problem, just label some data for a week and train a classifier.
— Richard (@RichardSocher) March 10, 2017
Вместо того, чтобы тратить месяц на формулирование задачи машинного обучения без учителя, просто потратьте неделю на то, чтобы разметить данные, и обучите классификатор.
Шаг 2. Очистите ваши данные
Правило номер один: «Ваша модель сможет стать лишь настолько хороша,
насколько хороши ваши данные»
Одним из ключевых навыков профессионального Data Scientist является знание о том, что должно быть следующим шагом — работа над моделью или над данными. Как показывает практика, сначала лучше взглянуть на сами данные, а только потом произвести их очистку.
Далее следует чеклист, который используется при очистке наших данных (подробности можно посмотреть в коде).
- Удалить все нерелевантные символы (например, любые символы, не относящиеся к цифро-буквенным).
- Токенизировать текст, разделив его на индивидуальные слова.
- Удалить нерелевантные слова — например, упоминания в Twitter или URL-ы.
- Перевести все символы в нижний регистр для того, чтобы слова «привет», «Привет» и «ПРИВЕТ» считались одним и тем же словом.
- Рассмотрите возможность совмещения слов, написанных с ошибками, или имеющих альтернативное написание (например, «круто»/«круть»/ «круууто»)
- Рассмотрите возможность проведения лемматизации, т. е. сведения различных форм одного слова к словарной форме (например, «машина» вместо «машиной», «на машине», «машинах» и пр.)
После того, как мы пройдемся по этим шагам и выполним проверку на дополнительные ошибки, мы можем начинать использовать чистые, помеченные данные для обучения моделей.
Шаг 3. Выберите хорошее представление данных
В качестве ввода модели машинного обучения принимают числовые значения. Например, модели, работающие с изображениями, принимают матрицу, отображающую интенсивность каждого пикселя в каждом канале цвета.
Улыбающееся лицо, представленное в виде массива чисел
Наш датасет представляет собой список предложений, поэтому для того, чтобы наш алгоритм мог извлечь паттерны из данных, вначале мы должны найти способ представить его таким образом, чтобы наш алгоритм мог его понять.
One-hot encoding («Мешок слов»)
Естественным путем отображения текста в компьютерах является кодирование каждого символа индивидуально в виде числа (пример подобного подхода — кодировка ASCII). Если мы «скормим» подобную простую репрезентацию классификатору, он будет должен изучить структуру слов с нуля, основываясь лишь на наших данных, что на большинстве датасетов невозможно. Следовательно, мы должны использовать более высокоуровневый подход.
Например, мы можем построить словарь всех уникальных слов в нашем датасете, и ассоциировать уникальный индекс каждому слову в словаре. Каждое предложение тогда можно будет отобразить списком, длина которого равна числу уникальных слов в нашем словаре, а в каждом индексе в этом списке будет хранится, сколько раз данное слово встречается в предложении. Эта модель называется «Мешком слов» (Bag of Words), поскольку она представляет собой отображение полностью игнорирущее порядок слов предложении.
Представление предложений в виде «Мешка слов». Исходные предложения указаны слева, их представление — справа. Каждый индекс в векторах представляет собой одно конкретное слово.
Визуализируем векторные представления
В словаре «Катастрофы в социальных медиа» содержится около 20 000 слов. Это означает, что каждое предложение будет отражено вектором длиной 20 000. Этот вектор будет содержать преимущественно нули, поскольку каждое предложение содержит лишь малое подмножество из нашего словаря.
Для того, чтобы выяснить, захватывают ли наши векторные представления (embeddings), релевантную нашей задаче информацию (например, имеют ли твиты отношение к катастрофам или нет), стоит попробовать визуализировать их и посмотреть, насколько хорошо разделены эти классы. Поскольку словари обычно являются очень большими и визуализация данных на 20 000 измерений невозможна, подходы вроде метода главных компонент (PCA) помогают спроецировать данные на два измерения.
Визуализация векторных представлений для «мешка слов»
Судя по получившемуся графику, не похоже, что два класса разделены как следует — это может быть особенностью нашего представления или просто эффектом сокращения размерности. Для того, чтобы выяснить, являются ли для нас полезными возможности «мешка слов», мы можем обучить классификатор, основанный на них.
Шаг 4. Классификация
Когда вы в первый раз принимаетесь за задачу, общепринятой практикой является начать с самого простого способа или инструмента, который может решить эту задачу. Когда дело касается классификации данных, наиболее распространенным способом является логистическая регрессия из-за своей универсальности и легкости толкования. Ее очень просто обучить, и ее результаты можно интерпретировать, поскольку вы можете с легкостью извлечь все самые важные коэффициенты из модели.
Разобьем наши данные на обучающую выборку, которую мы будем использовать для обучения нашей модели, и тестовую — для того, чтобы посмотреть, насколько хорошо наша модель обобщается на данные, которые не видела до этого. После обучения мы получаем точность в 75.4%. Не так уж и плохо! Угадывание самого частого класса («нерелеватно») дало бы нам лишь 57%.
После обучения мы получаем точность в 75.4%. Не так уж и плохо! Угадывание самого частого класса («нерелеватно») дало бы нам лишь 57%.
Однако, даже если результата с 75% точностью было бы достаточно для наших нужд, мы никогда не должны использовать модель в продакшне без попытки понять ее.
Шаг 5. Инспектирование
Матрица ошибок
Первый шаг — это понять, какие типы ошибок совершает наша модель, и с какими видами ошибок нам в дальнейшем хотелось бы встречаться реже всего. В случае нашего примера, ложно-положительные результаты классифицируют нерелевантный твит в качестве катастрофы, ложно-отрицательные — классифицируют катастрофу как нерелевантный твит. Если нашим приоритетом является реакция на каждое потенциальное событие, то мы захотим снизить наши ложно-отрицательные срабатывания. Однако, если мы ограничены в ресурсах, то мы можем приоритезировать более низкую частоту ложно-отрицательных срабатываний для уменьшения вероятности ложной тревоги. Хорошим способом визуализации данной информации является использование матрицы ошибок, которая сравнивает предсказания, сделанные нашей моделью, с реальными метками. В идеале, данная матрица будет представлять собой диагональную линию, идущую из левого верхнего до нижнего правого угла (это будет означать, что наши предсказания идеально совпали с правдой).
Хорошим способом визуализации данной информации является использование матрицы ошибок, которая сравнивает предсказания, сделанные нашей моделью, с реальными метками. В идеале, данная матрица будет представлять собой диагональную линию, идущую из левого верхнего до нижнего правого угла (это будет означать, что наши предсказания идеально совпали с правдой).
Наш классификатор создает больше ложно-отрицательных, чем ложно-положительных результатов (пропорционально). Другими словами, самая частая ошибка нашей модели состоит в неточной классификации катастроф как нерелевантных. Если ложно-положительные отражают высокую стоимость для правоохранительных органов, то это может стать хорошим вариантом для нашего классификатора.
Объяснение и интерпретация нашей модели
Чтобы произвести валидацию нашей модели и интерпретировать ее предсказания, важно посмотреть на то, какие слова она использует для принятия решений. Если наши данные смещены, наш классификатор произведет точные предсказания на выборочных данных, но модель не сможет достаточно хорошо обобщить их в реальном мире. На диаграмме ниже показаны наиболее значимые слова для классов катастроф и нерелевантных твитов. Составление диаграмм, отражающих значимость слов, не составляет трудностей в случае использования «мешка слов» и логистической регрессии, поскольку мы просто извлекаем и ранжируем коэффициенты, которые модель использует для своих предсказаний.
На диаграмме ниже показаны наиболее значимые слова для классов катастроф и нерелевантных твитов. Составление диаграмм, отражающих значимость слов, не составляет трудностей в случае использования «мешка слов» и логистической регрессии, поскольку мы просто извлекаем и ранжируем коэффициенты, которые модель использует для своих предсказаний.
«Мешок слов»: значимость слов
Наш классификатор верно нашел несколько паттернов (hiroshima — «Хиросима», massacre — «резня»), но ясно видно, что он переобучился на некоторых бессмысленных терминах («heyoo», «x1392»). Итак, сейчас наш «мешок слов» имеет дело с огромным словарем из различных слов и все эти слова для него равнозначны. Однако, некоторые из этих слов встречаются очень часто, и лишь добавляют шума нашим предсказаниям. Поэтому далее мы постараемся найти способ представить предложения таким образом, чтобы они могли учитывать частоту слов, и посмотрим, сможем ли мы получить больше полезной информации из наших данных.
Шаг 6. Учтите структуру словаря
TF-IDF
Чтобы помочь нашей модели сфокусироваться на значимых словах, мы можем использовать скоринг TF-IDF (Term Frequency, Inverse Document Frequency) поверх нашей модели «мешка слов». TF-IDF взвешивает на основании того, насколько они редки в нашем датасете, понижая в приоритете слова, которые встречаются слишком часто и просто добавляют шум. Ниже приводится проекция метода главных компонент, позволяющая оценить наше новое представление.
Визуализация векторного представления с применением TF-IDF.
Мы можем наблюдать более четкое разделение между двумя цветами. Это свидетельствует о том, что нашему классификатору должно стать проще разделить обе группы. Давайте посмотрим, насколько улучшатся наши результаты. Обучив другую логистическую регрессию на наших новых векторных представлениях, мы получим точность в 76,2%.
Очень незначительное улучшение.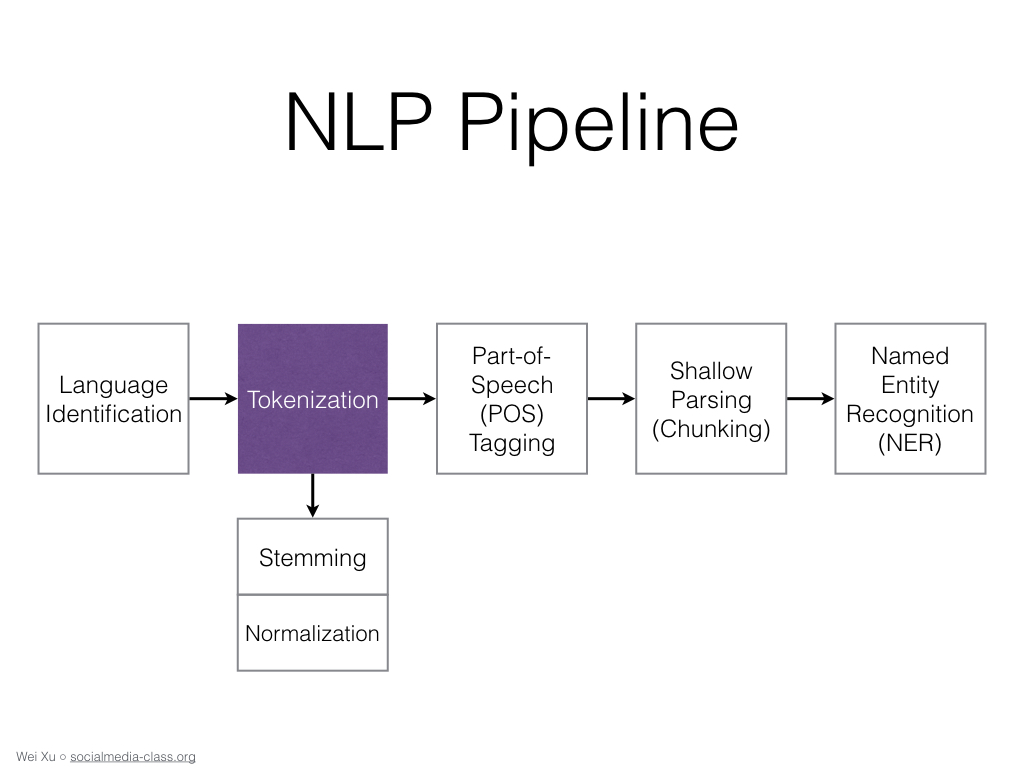 Может, наша модель хотя бы стала выбирать более важные слова? Если полученный результат по этой части стал лучше, и мы не даем модели «мошенничать», то можно считать этот подход усовершенствованием.
Может, наша модель хотя бы стала выбирать более важные слова? Если полученный результат по этой части стал лучше, и мы не даем модели «мошенничать», то можно считать этот подход усовершенствованием.
TF-IDF: Значимость слов
Выбранные моделью слова действительно выглядят гораздо более релевантными. Несмотря на то, что метрики на нашем тестовом множестве увеличились совсем незначительно, у нас теперь гораздо больше уверенности в использовании модели в реальной системе, которая будет взаимодействовать с клиентами.
Шаг 7. Применение семантики
Word2Vec
Наша последняя модель смогла «выхватить» слова, несущие наибольшее значение. Однако, скорее всего, когда мы выпустим ее в продакшн, она столкнется со словами, которые не встречались в обучающей выборке — и не сможет точно классифицировать эти твиты, даже если она видела весьма похожие слова во время обучения.
Чтобы решить данную проблему, нам потребуется захватить семантическое (смысловое) значение слов — это означает, что для нас важно понимать, что слова «хороший» и «позитивный» ближе друг к другу, чем слова «абрикос» и «континент». Мы воспользуемся инструментом Word2Vec, который поможет нам сопоставить значения слов.
Мы воспользуемся инструментом Word2Vec, который поможет нам сопоставить значения слов.
Использование результатов предварительного обучения
Word2Vec — это техника для поиска непрерывных отображений для слов. Word2Vec обучается на прочтении огромного количества текста с последующим запоминанием того, какое слово возникает в схожих контекстах. После обучения на достаточном количестве данных, Word2Vec генерирует вектор из 300 измерений для каждого слова в словаре, в котором слова со схожим значением располагаются ближе друг к другу.
Авторы публикации на тему непрерывных векторных представлений слов выложили в открытый доступ модель, которая была предварительно обучена на очень большом объеме информации, и мы можем использовать ее в нашей модели, чтобы внести знания о семантическом значении слов. Предварительно обученные векторы можно взять в репозитории, упомянутом в статье по ссылке.
Отображение уровня предложений
Быстрым способом получить вложения предложений для нашего классификатора будет усреднение оценок Word2Vec для всех слов в нашем предложении.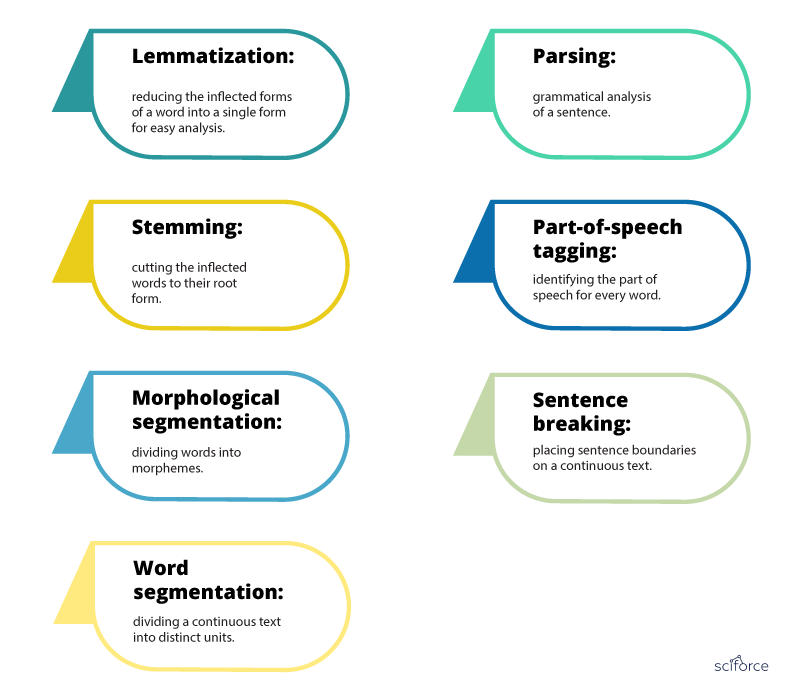 Это все тот же подход, что и с «мешком слов» ранее, но на этот раз мы теряем только синтаксис нашего предложения, сохраняя при этом семантическую (смысловую) информацию.
Это все тот же подход, что и с «мешком слов» ранее, но на этот раз мы теряем только синтаксис нашего предложения, сохраняя при этом семантическую (смысловую) информацию.
Векторные представления предложений в Word2Vec
Вот визуализация наших новых векторных представлений после использования перечисленных техник:
Визуализация векторных представлений Word2Vec.
Теперь две группы цветов выглядят разделенными еще сильнее, и это должно помочь нашему классификатору найти различие между двумя классами. После обучения той же модели в третий раз (логистическая регрессия), мы получаем точность в 77,7% — и это наш лучший результат на данный момент! Настало время изучить нашу модель.
Компромисс между сложностью и объяснимостью
Поскольку наши векторные представления более не представлены в виде вектора с одним измерением на слово, как было в предыдущих моделях, теперь тяжелее понять, какие слова наиболее релевантны для нашей классификации. Несмотря на то, что мы по-прежнему обладаем доступом к коэффициентам нашей логистической регрессии, они относятся к 300 измерениям наших вложений, а не к индексам слов.
Несмотря на то, что мы по-прежнему обладаем доступом к коэффициентам нашей логистической регрессии, они относятся к 300 измерениям наших вложений, а не к индексам слов.
Для столь небольшого прироста точности, полная потеря возможности объяснить работу модели — это слишком жесткий компромисс. К счастью, при работе с более сложными моделями мы можем использовать интерпретаторы наподобие LIME, которые применяются для того, чтобы получить некоторое представление о том, как работает классификатор.
LIME
LIME доступен на Github в виде открытого пакета. Данный интерпретатор, работающий по принципу черного ящика, позволяет пользователям объяснять решения любого классификатора на одном конкретном примере при помощи изменения ввода (в нашем случае — удаления слова из предложения) и наблюдения за тем, как изменяется предсказание.
Давайте взглянем на пару объяснений для предложений из нашего датасета.
Правильные слова катастроф выбраны для классификации как «релевантные».
Здесь вклад слов в классификацию выглядит менее очевидным.
Впрочем, у нас нет достаточного количества времени, чтобы исследовать тысячи примеров из нашего датасета. Вместо этого, давайте запустим LIME на репрезентативной выборке тестовых данных, и посмотрим, какие слова встречаются регулярно и вносят наибольший вклад в конечный результат. Используя данный подход, мы можем получить оценки значимости слов аналогично тому, как мы делали это для предыдущих моделей, и валидировать предсказания нашей модели.
Похоже на то, что модель выбирает высоко релевантные слова и соответственно принимает понятные решения. По сравнению со всеми предыдущими моделями, она выбирает наиболее релевантные слова, поэтому лучше будет отправить в продакшн именно ее.
Шаг 8. Использование синтаксиса при применении end-to-end подходов
Мы рассмотрели быстрые и эффективные подходы для генерации компактных векторных представлений предложений. Однако, опуская порядок слов, мы отбрасываем всю синтаксическую информацию из наших предложений. Если эти методы не дают достаточных результатов, вы можете использовать более сложную модель, которая принимает целые выражения в качестве ввода и предсказывает метки, без необходимости построения промежуточного представления. Распространенный для этого способ состоит в рассмотрении предложения как последовательности индивидуальных векторов слов с использованием или Word2Vec, или более свежих подходов вроде GloVe или CoVe. Именно этим мы и займемся далее.
Однако, опуская порядок слов, мы отбрасываем всю синтаксическую информацию из наших предложений. Если эти методы не дают достаточных результатов, вы можете использовать более сложную модель, которая принимает целые выражения в качестве ввода и предсказывает метки, без необходимости построения промежуточного представления. Распространенный для этого способ состоит в рассмотрении предложения как последовательности индивидуальных векторов слов с использованием или Word2Vec, или более свежих подходов вроде GloVe или CoVe. Именно этим мы и займемся далее.
Высокоэффективная архитектура обучения модели без дополнительной предварительной и последующей обработки (end-to-end, источник)
Сверточные нейронные сети для классификации предложений (CNNs for Sentence Classification) обучаются очень быстро и могут сослужить отличную службу в качестве входного уровня в архитектуре глубокого обучения. Несмотря на то, что сверточные нейронные сети (CNN) в основном известны своей высокой производительностью на данных-изображениях, они показывают превосходные результаты при работе с текстовыми данными, и обычно гораздо быстрее обучаются, чем большинство сложных подходов NLP (например, LSTM-сети и архитектуры Encoder/Decoder ). Эта модель сохраняет порядок слов и обучается ценной информации о том, какие последовательности слов служат предсказанием наших целевых классов. В отличии от предыдущих моделей, она в курсе существования разницы между фразами «Лёша ест растения» и «Растения едят Лёшу».
Эта модель сохраняет порядок слов и обучается ценной информации о том, какие последовательности слов служат предсказанием наших целевых классов. В отличии от предыдущих моделей, она в курсе существования разницы между фразами «Лёша ест растения» и «Растения едят Лёшу».
Обучение данной модели не потребует сильно больше усилий по сравнению с предыдущими подходами (смотрите код), и, в итоге, мы получим модель, которая работает гораздо лучше предыдущей, позволяя получить точность в 79,5%. Как и с моделями, которые мы рассмотрели ранее, следующим шагом должно быть исследование и объяснение предсказаний с помощью методов, которые мы описали выше, чтобы убедиться в том, что модель является лучшим вариантом, который мы можем предложить пользователям. К этому моменту вы уже должны чувствовать себя достаточно уверенными, чтобы справиться с последующими шагами самостоятельно.
В заключение
Итак, краткое содержание подхода, который мы успешно применили на практике:
- начинаем с быстрой и простой модели;
- объясняем ее предсказания;
- понимаем, какие разновидности ошибок она делает;
- используем полученные знания для принятия решения о следующем шаге — будь то работа над данными, или над более сложной моделью.

Данные подходы мы рассмотрели на конкретном примере с использованием моделей, заточенных на распознавание, понимание и использование коротких текстов — например, твитов; однако, эти же идеи широко применимы к множеству различных задач.
Как уже отмечалось в статье, кто угодно может извлечь пользу, применив методы машинного обучения, тем более в мире интернета, со всем разнообразием аналитических данных. Поэтому темы искусственного интеллекта и машинного обучения непременно обсуждаются на наших конференциях РИТ++ и Highload++, причем с совершенно практической точки зрения, как и в этой статье. Вот, например, видео нескольких прошлогодних выступлений:
- Поиск признаков мошенничества в убытках по медицинскому страхованию / Василий Рязанов (Allianz)
- Ранжирование откликов соискателей с помощью машинного обучения / Сергей Сайгушкин (Superjob)
- Машинное обучение в электронной коммерции / Александр Сербул (1С-Битрикс)
- Применение машинного обучения для генерации структурированных сниппетов / Никита Спирин (Datastars)
А программа майского фестиваля РИТ++ и июньского Highload++ Siberia уже в пути, за текущим состоянием можно следить на сайтах конференций или подписаться на рассылку, и мы будем периодически присылать анонсы одобренных докладов, чтобы вам ничего не пропустить.

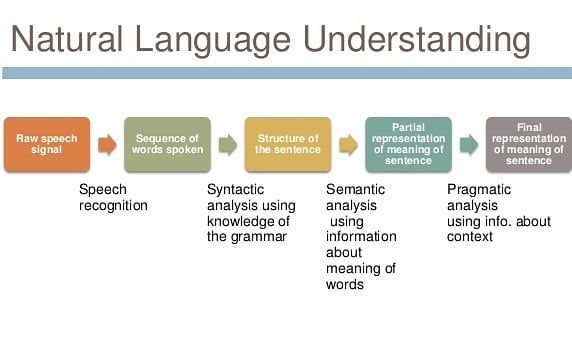
NLP (Natural Language Processing) — обработка естественного языка
NLP (Natural Language Processing, обработка естественного языка) — это направление в машинном обучении, посвященное распознаванию, генерации и обработке устной и письменной человеческой речи. Находится на стыке дисциплин искусственного интеллекта и лингвистики.
Инженеры-программисты разрабатывают механизмы, позволяющие взаимодействовать компьютерам и людям посредством естественного языка. Благодаря NLP компьютеры могут читать, интерпретировать, понимать человеческий язык, а также выдавать ответные результаты. Как правило, обработка основана на уровне интеллекта машины, расшифровывающего сообщения человека в значимую для нее информацию.
Процесс машинного понимания с применением алгоритмов обработки естественного языка может выглядеть так:
- Речь человека записывается аудио-устройством.
- Машина преобразует слова из аудио в письменный текст.
- Система NLP разбирает текст на составляющие, понимает контекст беседы и цели человека.
- С учетом результатов работы NLP машина определяет команду, которая должна быть выполнена.

Подробнее
Приложения NLP окружают нас повсюду. Это поиск в Google или Яндексе, машинный перевод, чат-боты, виртуальные ассистенты вроде Siri, Алисы, Салюта от Сбера и пр. NLP применяется в digital-рекламе, сфере безопасности и многих других.
NLP применяется в digital-рекламе, сфере безопасности и многих других.
Технологии NLP используют как в науке, так и для решения коммерческих бизнес-задач: например, для исследования искусственного интеллекта и способов его развития, а также создания «умных» систем, работающих с естественными человеческими языками, от поисковиков до музыкальных приложений.
Раньше алгоритмам прописывали набор реакций на определенные слова и фразы, а для поиска использовалось сравнение. Это не распознавание и понимание текста, а реагирование на введенный набор символов. Такой алгоритм не смог бы увидеть разницы между столовой ложкой и школьной столовой.
NLP — другой подход. Алгоритмы обучают не только словам и их значениям, но и структуре фраз, внутренней логике языка, пониманию контекста. Чтобы понять, к чему относится слово «он» в предложении «человек носил костюм, и он был синий», машина должна иметь представление о свойствах понятий «человек» и «костюм». Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.
Чтобы научить этому компьютер, специалисты используют алгоритмы машинного обучения и методы анализа языка из фундаментальной лингвистики.
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует. Затем она выполняет действия на основе данных, которые получила.
Затем она выполняет действия на основе данных, которые получила.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Алгоритмы не работают с «сырыми» данными. Большая часть процесса — подготовка текста или речи, преобразование их в вид, доступный для восприятия компьютером.
Очистка. Из текста удаляются бесполезные для машины данные. Это большинство знаков пунктуации, особые символы, скобки, теги и пр. Некоторые символы могут быть значимыми в конкретных случаях. Например, в тексте про экономику знаки валют несут смысл.
Препроцессинг. Дальше наступает большой этап предварительной обработки — препроцессинга. Это приведение информации к виду, в котором она более понятна алгоритму. Популярные методы препроцессинга:
- приведение символов к одному регистру, чтобы все слова были написаны с маленькой буквы;
- токенизация — разбиение текста на токены. Так называют отдельные компоненты — слова, предложения или фразы;
- тегирование частей речи — определение частей речи в каждом предложении для применения грамматических правил;
- лемматизация и стемминг — приведение слов к единой форме. Стемминг более грубый, он обрезает суффиксы и оставляет корни. Лемматизация — приведение слов к изначальным словоформам, часто с учетом контекста;
- удаление стоп-слов — артиклей, междометий и пр.;
- спелл-чекинг — автокоррекция слов, которые написаны неправильно.
 Так называют отдельные компоненты — слова, предложения или фразы;
Так называют отдельные компоненты — слова, предложения или фразы;Методы выбирают согласно задаче.
Векторизация. После предобработки на выходе получается набор подготовленных слов. Но алгоритмы работают с числовыми данными, а не с чистым текстом. Поэтому из входящей информации создают векторы — представляют ее как набор числовых значений.
Популярные варианты векторизации — «мешок слов» и «мешок N-грамм». В «мешке слов» слова кодируются в цифры. Учитывается только количество слова в тексте, а не их расположение и контекст. N-граммы — это группы из N слов. Алгоритм наполняет «мешок» не отдельными словами с их частотой, а группами по несколько слов, и это помогает определить контекст.
Применение алгоритмов машинного обучения. С помощью векторизации можно оценить, насколько часто в тексте встречаются слова. Но большинство актуальных задач сложнее, чем просто определение частоты — тут нужны продвинутые алгоритмы машинного обучения. В зависимости от типа конкретной задачи создается и настраивается своя отдельная модель.
Алгоритмы обрабатывают, анализируют и распознают входные данные, делают на их основе выводы. Это интересный и сложный процесс, в котором много математики и теории вероятностей.
Что это такое и как это работает?
Обработка естественного языка (NLP) позволяет машинам разбивать и интерпретировать человеческий язык.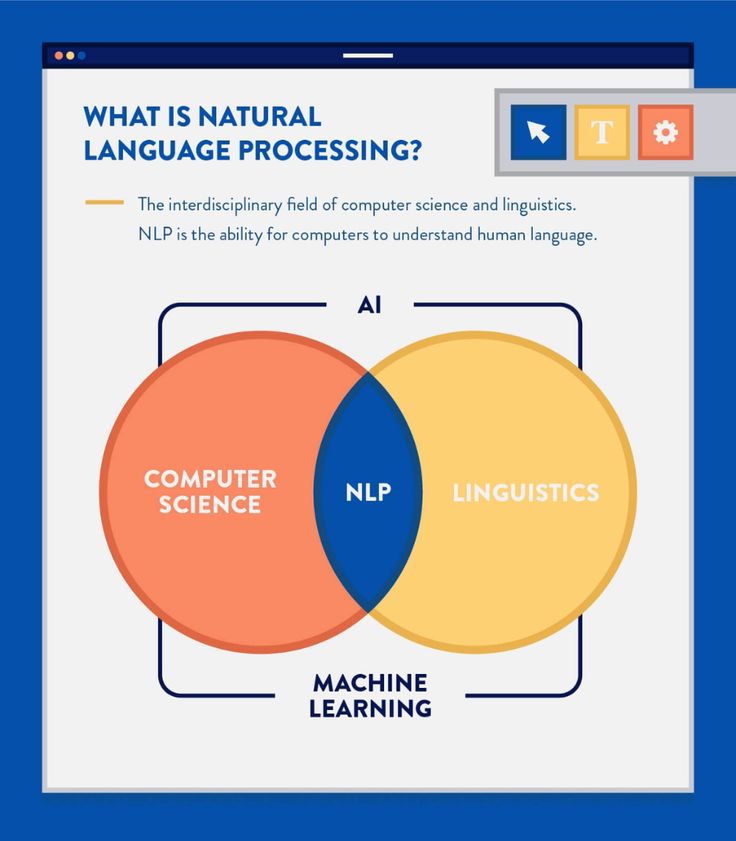 Он лежит в основе инструментов, которые мы используем каждый день — от программного обеспечения для перевода, чат-ботов, спам-фильтров и поисковых систем до программного обеспечения для исправления грамматики, голосовых помощников и инструментов мониторинга социальных сетей.
Он лежит в основе инструментов, которые мы используем каждый день — от программного обеспечения для перевода, чат-ботов, спам-фильтров и поисковых систем до программного обеспечения для исправления грамматики, голосовых помощников и инструментов мониторинга социальных сетей.
Начните свое путешествие по НЛП с инструментами без кода
ПОПРОБУЙТЕ СЕЙЧАС
В этом руководстве вы узнаете об основах обработки естественного языка и некоторых ее проблемах, а также откроете для себя самые популярные приложения НЛП в бизнесе. Наконец, вы сами убедитесь, насколько легко начать работу с инструментами обработки естественного языка без кода.
- Что такое обработка естественного языка (NLP)?
- Как работает обработка естественного языка?
- Проблемы обработки естественного языка
- Примеры обработки естественного языка
- Обработка естественного языка с помощью Python
- Учебное пособие по обработке естественного языка (NLP)
Что такое обработка естественного языка (NLP)?
Обработка естественного языка (NLP) — это область искусственного интеллекта (ИИ), которая делает человеческий язык понятным для машин. НЛП сочетает в себе мощь лингвистики и информатики для изучения правил и структуры языка и создания интеллектуальных систем (работающих на основе машинного обучения и алгоритмов НЛП), способных понимать, анализировать и извлекать смысл из текста и речи.
НЛП сочетает в себе мощь лингвистики и информатики для изучения правил и структуры языка и создания интеллектуальных систем (работающих на основе машинного обучения и алгоритмов НЛП), способных понимать, анализировать и извлекать смысл из текста и речи.
Для чего используется НЛП?
НЛП используется для понимания структуры и значения человеческого языка путем анализа различных аспектов, таких как синтаксис, семантика, прагматика и морфология. Затем информатика преобразует эти лингвистические знания в основанные на правилах алгоритмы машинного обучения, которые могут решать конкретные проблемы и выполнять желаемые задачи.
Возьмем, к примеру, Gmail. Электронные письма автоматически классифицируются как Рекламные акции , Социальные , Основные или Спам благодаря задаче NLP, называемой извлечением ключевых слов. «Читая» слова в строках темы и связывая их с заранее определенными тегами, машины автоматически узнают, к какой категории отнести электронные письма.
Преимущества НЛП
НЛП обладает многими преимуществами, но вот лишь несколько преимуществ высшего уровня, которые помогут вашему бизнесу стать более конкурентоспособным:
- Проведение крупномасштабного анализа. Обработка естественного языка помогает машинам автоматически понимать и анализировать огромные объемы неструктурированных текстовых данных, таких как комментарии в социальных сетях, заявки в службу поддержки, онлайн-обзоры, новостные отчеты и многое другое.
- Автоматизируйте процессы в режиме реального времени. Инструменты обработки естественного языка могут помочь машинам научиться сортировать и направлять информацию практически без участия человека — быстро, эффективно, точно и круглосуточно.
- Адаптируйте инструменты НЛП к своей отрасли. Алгоритмы обработки естественного языка могут быть настроены в соответствии с вашими потребностями и критериями, такими как сложный, специфичный для отрасли язык — даже сарказм и неправильно используемые слова.

Как работает обработка естественного языка?
Используя векторизацию текста, инструменты НЛП преобразуют текст во что-то, что может понять машина, затем алгоритмы машинного обучения получают обучающие данные и ожидаемые выходные данные (теги), чтобы обучить машины проводить ассоциации между конкретным вводом и соответствующим ему выводом. Затем машины используют методы статистического анализа для создания своего собственного «банка знаний» и определяют, какие функции лучше всего представляют тексты, прежде чем делать прогнозы для невидимых данных (новых текстов):
модели анализа текста будут.
Анализ настроений (показан на диаграмме выше) — одна из самых популярных задач НЛП, в которой модели машинного обучения обучаются классифицировать текст по полярности мнений (положительные, отрицательные, нейтральные и все промежуточные).
Попробуйте самостоятельно провести анализ настроений, набрав текст в модели НЛП ниже
Протестируйте с помощью собственного текста
Это лучший инструмент для анализа настроений!!!Результаты
Positive99. 1%
1%
Самым большим преимуществом моделей машинного обучения является их способность учиться самостоятельно, без необходимости определять правила вручную. Вам просто нужен набор соответствующих обучающих данных с несколькими примерами для тегов, которые вы хотите проанализировать. А с помощью передовых алгоритмов глубокого обучения вы можете объединять несколько задач обработки естественного языка, таких как анализ тональности, извлечение ключевых слов, классификация тем, обнаружение намерений и т. д., чтобы работать одновременно и получать очень подробные результаты.
Общие задачи и методы НЛП
Многие задачи обработки естественного языка включают синтаксический и семантический анализ, используемый для разбиения человеческого языка на машиночитаемые фрагменты.
Синтаксический анализ , также известный как синтаксический анализ или синтаксический анализ, идентифицирует синтаксическую структуру текста и отношения зависимости между словами, представленные на диаграмме, называемой деревом синтаксического анализа.
Семантический анализ фокусируется на определении значения языка. Однако, поскольку язык многозначен и неоднозначен, семантика считается одной из самых сложных областей НЛП.
Семантические задания анализируют структуру предложений, взаимодействие слов и связанные с ними понятия, пытаясь раскрыть значение слов, а также понять тему текста.
Ниже мы перечислили некоторые из основных подзадач как семантического, так и синтаксического анализа:
Токенизация
Токенизация — важная задача обработки естественного языка, используемая для разбиения строки слов на семантически полезные единицы, называемые токены .
Токенизация предложений разделяет предложения в тексте, а токенизация слов разделяет слова внутри предложения. Как правило, токены слов разделяются пробелами, а токены предложений — точками. Однако вы можете выполнять высокоуровневую токенизацию для более сложных структур, таких как слова, которые часто встречаются вместе, иначе называемые словосочетаниями (например, New York ).
Пример того, как разбиение слов упрощает текст:
Вот пример того, как разбиение слов упрощает текст:
Обслуживание клиентов не может быть лучше! = «обслуживание клиентов» «не может» «не быть» «лучше».
Тегирование части речи
Тегирование части речи (сокращенно PoS-тегирование) предполагает добавление категории части речи к каждому маркеру в тексте. Некоторые распространенные теги PoS: глагол , прилагательное , существительное , местоимение , союз , предлог , пересечение и другие. В этом случае приведенный выше пример будет выглядеть так:
«Обслуживание клиентов»: СУЩЕСТВИТЕЛЬНОЕ, «может»: ГЛАГОЛ, «не»: НАРЕЧИЕ, быть»: ГЛАГОЛ, «лучше»: ПРИЛАГАТЕЛЬНОЕ, «!»: ПУНКТУАЦИЯ
Маркировка PoS полезна для определения отношений между словами и, следовательно, понимать смысл предложений.
Анализ зависимостей
Грамматика зависимостей относится к способу соединения слов в предложении. Таким образом, синтаксический анализатор зависимостей анализирует, как «главные слова» связаны и изменяются другими словами, а также понимает синтаксическую структуру предложения:
Таким образом, синтаксический анализатор зависимостей анализирует, как «главные слова» связаны и изменяются другими словами, а также понимает синтаксическую структуру предложения:
Анализ избирательного округа
Анализ избирательного округа направлен на визуализацию всей синтаксической структуры предложения путем определения грамматики структуры фразы. Он состоит из использования абстрактных терминальных и нетерминальных узлов, связанных со словами, как показано в этом примере:
Вы можете попробовать различные алгоритмы и стратегии синтаксического анализа в зависимости от характера текста, который вы собираетесь анализировать, и уровня сложности, с которым вы работаете. хотел бы достичь.
Лемматизация и стемминг
Когда мы говорим или пишем, мы склонны использовать флективные формы слова (слова в их различных грамматических формах). Чтобы сделать эти слова более понятными для компьютеров, НЛП использует лемматизацию и выделение корней, чтобы преобразовать их обратно в корневую форму.
Слово в том виде, в каком оно появляется в словаре – его корневая форма – называется леммой. Например, термины «есть, есть, есть, были и были», группируются под леммой «быть». Итак, если мы применим эту лемматизацию к «У африканских слонов по четыре когтя на передних лапах», результат будет выглядеть примерно так:
У африканских слонов по четыре когтя на передних лапах = «африканский», «слон», «есть», «4», «гвоздь», «на», «их», «нога»]
Этот пример полезен, чтобы увидеть, как лемматизация изменяет предложение, используя его базовую форму (например, слово «ноги» было изменено на «нога»)
Когда мы обращаемся к основам, корневая форма слова называется основой. Основа «обрезает» слова, поэтому основы слов не всегда могут быть семантически правильными.
Например, если объединить слова «консультироваться», «консультант», «консалтинг» и «консультанты», получится корневая форма «консультироваться».
В то время как лемматизация основана на словаре и выбирает подходящую лемму в зависимости от контекста, выделение корней работает с отдельными словами без учета контекста. Например, в предложении:
Например, в предложении:
«Это лучше»
Слово «лучше» преобразуется в слово «хорошо» с помощью лемматизатора, но не изменяется по корню. Несмотря на то, что стеммеры могут давать менее точные результаты, их проще построить и они работают быстрее, чем лемматизаторы. Но лемматизаторы рекомендуются, если вы ищете более точные лингвистические правила.
Удаление стоп-слов
Удаление стоп-слов — важный шаг в обработке текста НЛП. Он включает в себя отфильтровывание часто встречающихся слов, которые практически не добавляют семантической ценности предложению, например, which to, at, for, is, и т. д.
Вы даже можете настроить списки стоп-слов, чтобы включить слова, которые вы хочу игнорировать.
Допустим, вы хотите классифицировать заявки в службу поддержки клиентов по их темам. В этом примере: «Здравствуйте, у меня проблемы со входом в систему с моим новым паролем» , может быть полезно удалить стоп-слова, такие как «привет» , «я» , «ам» , «с» , «мой» , так что у вас останутся слова, которые помогите разобраться в теме тикета: «беда» , «вход» , «новый» , «пароль» .
Word Sense Disambiguation
В зависимости от контекста слова могут иметь разные значения. Возьмем слово «книга» , например:
- Вы должны прочитать эту книгу ; это отличный роман!
- Вам следует забронировать рейсы как можно скорее.
- Вы должны закрыть книги до конца года.
- Вы должны делать все по книге , чтобы избежать возможных осложнений.
Существует два основных метода устранения неоднозначности смысла слов (WSD): основанный на знаниях (или словарный подход) или контролируемый подход . Первый пытается сделать вывод о значении, наблюдая словарные определения неоднозначных терминов в тексте, а второй основан на алгоритмах обработки естественного языка, которые извлекают уроки из обучающих данных.
Распознавание именованных объектов (NER)
Распознавание именованных объектов является одной из самых популярных задач семантического анализа и включает в себя извлечение объектов из текста. Сущностями могут быть имена, места, организации, адреса электронной почты и многое другое.
Сущностями могут быть имена, места, организации, адреса электронной почты и многое другое.
Извлечение отношений, еще одна подзадача НЛП, идет еще дальше и находит отношения между двумя существительными. Например, во фразе «Сьюзен живет в Лос-Анджелесе» человек (Сьюзен) связан с местом (Лос-Анджелес) семантической категорией «живет в».
Классификация текста
Классификация текста — это процесс понимания значения неструктурированного текста и организации его в предопределенные категории (теги). Одной из самых популярных задач классификации текста является анализ тональности, целью которого является категоризация неструктурированных данных по тональности.
Другие задачи классификации включают обнаружение намерений, моделирование темы и определение языка.
Проблемы обработки естественного языка
Существует множество проблем обработки естественного языка, но одна из основных причин сложности НЛП заключается просто в том, что человеческий язык неоднозначен.
Даже людям трудно правильно анализировать и классифицировать человеческий язык.
Возьмем, к примеру, сарказм. Как научить машину понимать выражение, которое говорит противоположное истине? В то время как люди легко уловили бы сарказм в этом комментарии, ниже было бы сложно научить машину интерпретировать эту фразу:
«Если бы мне давали по доллару за каждую умную вещь, которую вы говорите, я был бы беден».
Чтобы полностью понять человеческий язык, специалистам по обработке и анализу данных необходимо научить инструменты НЛП не ограничиваться определениями и порядком слов, понимать контекст, двусмысленность слов и другие сложные понятия, связанные с сообщениями. Но им также необходимо учитывать другие аспекты, такие как культура, происхождение и пол, при тонкой настройке моделей обработки естественного языка. Сарказм и юмор, например, могут сильно различаться в разных странах.
Обработка естественного языка и мощные алгоритмы машинного обучения (часто несколько совместно используемых) совершенствуются и упорядочивают хаос человеческого языка, вплоть до таких понятий, как сарказм. Мы также начинаем видеть новые тенденции в НЛП, поэтому мы можем ожидать, что НЛП произведет революцию в том, как люди и технологии взаимодействуют в ближайшем будущем и в будущем.
Мы также начинаем видеть новые тенденции в НЛП, поэтому мы можем ожидать, что НЛП произведет революцию в том, как люди и технологии взаимодействуют в ближайшем будущем и в будущем.
Примеры обработки естественного языка
Хотя обработка естественного языка продолжает развиваться, сегодня уже существует множество способов ее использования. Большую часть времени вы будете подвергаться обработке естественного языка, даже не осознавая этого.
Часто НЛП работает в фоновом режиме с инструментами и приложениями, которые мы используем каждый день, помогая компаниям улучшить наш опыт. Ниже мы выделили некоторые из наиболее распространенных и наиболее эффективных способов использования обработки естественного языка в повседневной жизни:
11 распространенных примеров НЛП
- Фильтры электронной почты
- Виртуальные помощники, голосовые помощники или умные колонки
- Онлайн-поиск Engines
- Предиктивный текст и автозамена
- Отслеживание настроений бренда в социальных сетях
- Сортировка отзывов клиентов
- Автоматизация процессов в службе поддержки
- Чат-боты
- Автоматическое обобщение
- Машинный перевод
- Генерация естественного языка использования НЛП. Когда они были впервые представлены, они были не совсем точными, но благодаря многолетнему обучению машинному обучению на миллионах выборок данных электронные письма в наши дни редко попадают не в тот почтовый ящик.
Виртуальные помощники, голосовые помощники или умные колонки
Наиболее распространенными из них являются Siri от Apple и Alexa от Amazon. Виртуальные помощники используют технологию машинного обучения NLP для понимания и автоматической обработки голосовых запросов. Алгоритмы обработки естественного языка позволяют индивидуально обучать помощников отдельными пользователями без дополнительного ввода, учиться на предыдущих взаимодействиях, вызывать связанные запросы и подключаться к другим приложениям.
Ожидается, что использование голосовых помощников будет продолжать расти в геометрической прогрессии, поскольку они используются для управления домашними системами безопасности, термостатами, освещением и автомобилями — даже чтобы вы знали, что у вас заканчивается в холодильнике.
Онлайн-поисковики
Всякий раз, когда вы выполняете простой поиск в Google, вы используете машинное обучение НЛП. Они используют хорошо обученные алгоритмы, которые ищут не только связанные слова, но и намерения искателя. Результаты часто меняются ежедневно, следуя трендовым запросам и трансформируясь вместе с человеческим языком. Они даже учатся предлагать темы и предметы, связанные с вашим запросом, которые, возможно, даже не осознавали, что вас интересуют.
Предиктивный текст
Каждый раз, когда вы печатаете текст на своем смартфоне, вы видите НЛП в действии. Часто вам нужно набрать всего несколько букв слова, и приложение для обмена текстовыми сообщениями предложит вам правильный вариант. И чем больше вы пишете, тем точнее он становится, часто распознавая часто используемые слова и имена быстрее, чем вы можете их напечатать.
Интеллектуальный текст, автозамена и автозаполнение стали настолько точными в программах обработки текстов, таких как MS Word и Google Docs, что они могут заставить нас чувствовать, что нам пора вернуться в начальную школу.
Мониторинг настроений бренда в социальных сетях
Анализ настроений — это автоматизированный процесс классификации мнений в тексте как положительных, отрицательных или нейтральных. Его часто используют для отслеживания настроений в социальных сетях. Вы можете отслеживать и анализировать настроения в комментариях о вашем бренде в целом, продукте, конкретной функции или сравнивать свой бренд с конкурентами.
Представьте, что вы только что выпустили новый продукт и хотите определить первоначальную реакцию ваших клиентов. Возможно, клиент написал в Твиттере о своем недовольстве обслуживанием клиентов. Отслеживая анализ настроений, вы можете сразу обнаружить эти негативные комментарии и немедленно ответить.
Быстрая сортировка отзывов клиентов
Классификация текста — это основная задача НЛП, которая назначает предопределенные категории (теги) тексту на основе его содержания. Он отлично подходит для организации качественной обратной связи (обзоры продуктов, обсуждения в социальных сетях, опросы и т.
д.) по соответствующим темам или категориям отделов.Retently, платформа SaaS, использовала инструменты НЛП для классификации ответов NPS и мгновенного получения полезной информации:
Retently обнаружила наиболее актуальные темы, упомянутые клиентами, и какие из них они ценят больше всего. Ниже вы можете видеть, что большинство ответов относились к «функциям продукта», за которыми следуют «UX продукта» и «поддержка клиентов» (последние две темы были упомянуты в основном промоутерами).
Автоматизация процессов обслуживания клиентов
Другие интересные применения НЛП связаны с автоматизацией обслуживания клиентов. Эта концепция использует технологию на основе искусственного интеллекта для устранения или сокращения рутинных ручных задач в службе поддержки клиентов, экономя драгоценное время агентов и повышая эффективность процессов.
Согласно бенчмарку Zendesk, технологическая компания получает +2600 запросов в службу поддержки в месяц. Получение большого количества обращений в службу поддержки по разным каналам (электронная почта, социальные сети, чат и т.
д.) означает, что компаниям необходимо иметь стратегию классификации каждого поступающего обращения.Классификация текста позволяет компаниям автоматически маркировать входящие запросы в службу поддержки клиентов в соответствии с их темой, языком, настроением или срочностью. Затем на основе этих тегов они могут мгновенно направлять заявки наиболее подходящему пулу агентов.
Компания Uber разработала собственный рабочий процесс маршрутизации билетов, который включает маркировку билетов по стране, языку и типу (эта категория включает вложенные теги Водитель-партнер, Вопросы о платежах, Потерянные предметы и т. д. ), и в соответствии с некоторыми правилами приоритизации, такими как отправка запросов от новых клиентов ( New Driver-Partners ), отправляются в начало списка.
Чат-боты
Чат-бот — это компьютерная программа, имитирующая человеческий разговор. Чат-боты используют NLP, чтобы распознавать смысл предложения, определять релевантные темы и ключевые слова, даже эмоции, и предлагать лучший ответ на основе своей интерпретации данных.
Поскольку клиенты жаждут быстрой, персонализированной и круглосуточной поддержки, чат-боты стали героями стратегий обслуживания клиентов. Чат-боты сокращают время ожидания клиентов, предоставляя немедленные ответы, и особенно хорошо справляются с обработкой рутинных запросов (которые обычно представляют собой наибольший объем запросов в службу поддержки клиентов), позволяя агентам сосредоточиться на решении более сложных проблем. На самом деле, чат-боты могут решить до 80% обычных запросов в службу поддержки клиентов.
Помимо поддержки клиентов, чат-боты могут использоваться для рекомендации продуктов, предоставления скидок и бронирования, а также для многих других задач. Для этого большинство чат-ботов следуют простой логике «если/то» (они запрограммированы так, чтобы определять намерения и связывать их с определенным действием) или предоставляют набор вариантов на выбор.
Автоматическое суммирование
Автоматическое суммирование заключается в сокращении текста и создании новой краткой версии, содержащей наиболее важную информацию.
Это может быть особенно полезно для суммирования больших фрагментов неструктурированных данных, таких как научные статьи.Существует два разных способа использования НЛП для обобщения:
- Извлечение наиболее важной информации из текста и использование ее для создания резюме (резюмирование на основе извлечения)
- Применение методов глубокого обучения для перефразирования текста и создавать предложения, которых нет в первоисточнике (обобщение на основе абстракции) .
Автоматическое суммирование может быть особенно полезным для ввода данных, когда необходимая информация извлекается, например, из описания продукта и автоматически вводится в базу данных.
Машинный перевод
Возможность перевода текста и речи на разные языки всегда была одним из основных интересов в области НЛП. Начиная с первых попыток перевода текста с русского на английский в 1950-х годах и заканчивая современными нейронными системами глубокого обучения, машинный перевод (МТ) претерпел значительные улучшения, но по-прежнему сопряжен с проблемами.
Google Translate, Microsoft Translator и приложение для перевода Facebook — это лишь некоторые из ведущих платформ для универсального машинного перевода. В августе 2019 г., Модель машинного перевода Facebook AI с английского на немецкий заняла первое место в конкурсе, проводимом Конференцией по машинному обучению (WMT). Переводы, полученные с помощью этой модели, были определены организаторами как «сверхчеловеческие» и признаны намного превосходящими переводы, выполненные экспертами-людьми.
Еще одна интересная разработка в области машинного перевода связана с настраиваемыми системами машинного перевода, адаптированными к конкретной области и обученными понимать терминологию, связанную с определенной областью, такой как медицина, юриспруденция и финансы. Lingua Custodia, например, представляет собой инструмент машинного перевода, предназначенный для перевода технических финансовых документов.
Наконец, одно из последних нововведений машинного перевода — адаптивный машинный перевод, состоящий из систем, способных учиться на исправлениях в режиме реального времени.
Генерация естественного языка
Генерация естественного языка (NLG) — это подраздел НЛП, предназначенный для создания компьютерных систем или приложений, которые могут автоматически создавать все виды текстов на естественном языке, используя семантическое представление в качестве входных данных. Некоторые из приложений NLG — это ответы на вопросы и обобщение текста.
В 2019 году компания Open AI, занимающаяся искусственным интеллектом, выпустила GPT-2, систему генерации текста, которая представляет собой новаторское достижение в области ИИ и выводит область NLG на совершенно новый уровень. Система была обучена на огромном наборе данных из 8 миллионов веб-страниц и способна генерировать связные и высококачественные фрагменты текста (например, новостные статьи, рассказы или стихи) с минимальными подсказками.
Модель работает лучше, когда в нее входят популярные темы, широко представленные в данных (такие как Brexit, например), но она дает худшие результаты, когда запрашивается узкоспециализированный или технический контент.
Тем не менее, его возможности только начинают изучаться.Обработка естественного языка с помощью Python
Теперь, когда вы получили некоторое представление об основах НЛП и его текущих приложениях в бизнесе, вам может быть интересно, как применить НЛП на практике.
Существует множество библиотек с открытым исходным кодом, предназначенных для обработки естественного языка. Эти библиотеки бесплатны, гибки и позволяют вам создать полное и индивидуальное решение NLP.
Однако создание целой инфраструктуры с нуля требует многолетнего опыта работы с данными и программирования, или вам, возможно, придется нанять целые команды инженеров.
Инструменты SaaS, с другой стороны, представляют собой готовые к использованию решения, которые позволяют вам интегрировать НЛП в инструменты, которые вы уже используете, просто и с минимальной настройкой. Подключить инструменты SaaS к вашим любимым приложениям через их API очень просто, для этого требуется всего несколько строк кода.
Это отличная альтернатива, если вы не хотите тратить время и ресурсы на изучение машинного обучения или НЛП.Взгляните на дебаты «Создать или купить», чтобы узнать больше.
Вот список лучших инструментов НЛП:
- MonkeyLearn — это платформа SaaS, которая позволяет создавать настраиваемые модели обработки естественного языка для выполнения таких задач, как анализ настроений и извлечение ключевых слов. Разработчики могут подключать модели NLP через API в Python, а те, у кого нет навыков программирования, могут загружать наборы данных через интеллектуальный интерфейс или подключаться к повседневным приложениям, таким как Google Sheets, Excel, Zapier, Zendesk и другим.
- Natural Language Toolkit (NLTK) — это набор библиотек для создания программ на Python, которые могут решать широкий спектр задач NLP. Это самая популярная библиотека Python для НЛП, за ней стоит очень активное сообщество, и она часто используется в образовательных целях. Существует руководство и учебник по использованию NLTK, но это довольно крутая кривая обучения.
- SpaCy — бесплатная библиотека с открытым исходным кодом для расширенной обработки естественного языка в Python. Он был специально разработан для создания приложений НЛП, которые могут помочь вам понять большие объемы текста.
- TextBlob — это библиотека Python с простым интерфейсом для выполнения различных задач НЛП. Созданная на основе NLTK и другой библиотеки под названием Pattern, она интуитивно понятна и удобна для пользователя, что делает ее идеальной для начинающих. Узнайте больше о том, как использовать TextBlob и его функции.
Учебное пособие по обработке естественного языка
Решения SaaS, такие как MonkeyLearn, предлагают готовые к использованию шаблоны NLP для анализа определенных типов данных. В этом руководстве ниже мы покажем вам, как выполнять анализ тональности в сочетании с извлечением ключевых слов с использованием нашего индивидуального шаблона.
1. Выберите ключевое слово + шаблон анализа тональности
2. Загрузите текстовые данные
Если у вас нет файла CSV, используйте наш пример набора данных.
3. Сопоставьте столбцы CSV с полями панели мониторинга
В этом шаблоне есть только одно поле: текст . Если в вашем наборе данных несколько столбцов, выберите столбец с текстом, который вы хотите проанализировать.
4. Назовите свой рабочий процесс
5. Подождите, пока ваши данные будут импортированы
6. Изучите панель инструментов!
Вы можете:
- Фильтровать по настроению или ключевому слову.
- Поделитесь по электронной почте с другими коллегами.
Заключительные слова об обработке естественного языка
Обработка естественного языка меняет способ анализа и взаимодействия с языковыми данными с помощью обучающих машин, чтобы понимать текст и речь и выполнять автоматизированные задачи, такие как перевод, обобщение, классификация и добыча.
Не так давно идея компьютеров, способных понимать человеческий язык, казалась невозможной. Однако за относительно короткое время — благодаря исследованиям и разработкам в области лингвистики, компьютерных наук и машинного обучения — НЛП стало одной из самых многообещающих и быстрорастущих областей в области ИИ.
По мере развития технологий НЛП становится все более доступным. Благодаря программному обеспечению на основе НЛП типа «включай и работай», такому как MonkeyLearn, компаниям становится проще создавать индивидуальные решения, которые помогают автоматизировать процессы и лучше понимать своих клиентов.
Готовы начать работу с НЛП?
Запросите демонстрацию и сообщите нам, как мы можем помочь вам начать работу.
Обработка естественного языка: задачи и области применения
Содержание
- How companies use NLP
- Key application areas of NLP
- Challenges blocking NLP from mass adoption
- Avenga’s nlp expertise in healthcare
- Conclusion
As companies grasp unstructured data’s ценность и решения на основе ИИ для его монетизации, рынок обработки естественного языка, как подобласть ИИ, продолжает быстро расти.
Эта технология, которая принесет к 2025 году многообещающие 43 миллиарда долларов, заслуживает внимания и инвестиций. Как предприятия могут использовать НЛП? Каковы основные области приложений для обработки естественного языка? Имея непосредственный опыт использования НЛП в сфере здравоохранения, Avenga может поделиться своим пониманием этой темы.Как компании используют НЛП
Количество и доступность неструктурированных данных растут в геометрической прогрессии, раскрывая их ценность для обработки, анализа и потенциал для принятия решений в компаниях. НЛП — идеальный инструмент для работы с объемами ценных данных, хранящихся в твитах, блогах, изображениях, видео и профилях в социальных сетях. Таким образом, любой бизнес, который видит ценность в анализе данных — от короткого текста до нескольких документов, которые необходимо обобщить, — найдет НЛП полезным.
Передовые системы часто включают в себя алгоритмы НЛП и машинного обучения, что увеличивает количество задач, которые могут выполнять эти системы ИИ.
В этом случае они разгадывают человеческий язык, помечая его, анализируя, выполняя определенные действия на основе результатов и т. д. Вспомните, например, Siri или Alexa. Это помощники на основе искусственного интеллекта, которые интерпретируют человеческую речь с помощью алгоритмов НЛП и распознавания голоса, а затем реагируют на основе предыдущего опыта, полученного с помощью алгоритмов машинного обучения.Чтобы углубиться, роль машинного обучения для обработки естественного языка и анализа текста заключается в улучшении функций НЛП и превращении неструктурированного текста в ценную информацию. Итак, общий подход выглядит так: вы обучаете модель выполнению задачи, затем проверяете правильность модели и применяете ее к проблеме. Вот основные задачи, решаемые с помощью НЛП.
→ Узнайте, как техника социального графа НЛП помогает оценивать базы данных пациентов и может помочь организациям, занимающимся клиническими исследованиями, добиться успеха в анализе клинических испытаний.
Ключевые области применения НЛП
- Поиск. Алгоритмы NLP идентифицируют определенные элементы в тексте. Вы можете искать ключевые слова в документе, запускать контекстный поиск синонимов, обнаруживать слова с ошибками или похожие записи и многое другое.
- Машинный перевод. Обычно это включает в себя перевод одного естественного языка на другой с сохранением смысла и созданием беглого текста в результате. Здесь используются разные методы и подходы: основанный на правилах, статистический и нейронный машинный перевод.
- Подведение итогов. Алгоритмы NLP можно использовать для создания сокращенной версии статьи, документа, количества статей и т. д. с включением основных моментов и ключевых идей. Существует два основных подхода: абстрактное и экстрактивное обобщение. В первом случае модель НЛП создает совершенно новое резюме с точки зрения фраз и предложений, используемых в анализируемом тексте. Во втором случае модель извлекает фразы и предложения из существующего текста и группирует их в резюме.
- Распознавание именованных объектов. NER — это извлечение, идентификация и категоризация сущностей. Он включает в себя извлечение названий местоположений, людей и вещей из текста и помещение их в определенные категории — «Лицо», «Компания», «Время», «Местоположение» и т. д. Варианты использования могут включать классификацию контента для SEO, поддержку клиентов, анализ лабораторных отчетов пациентов, научные исследования. и другие.
- Маркировка частей речи (POS). Чтобы построить NER и извлечь отношения между словами, модели NLP сначала необходимо пометить POS: она группирует слова из текста в соответствии с частями речи на основе определения слова и контекста. Методы и модели тегов POS включают лексические, основанные на правилах, вероятностные методы, а также использование рекуррентных нейронных сетей и многое другое.
- Поиск информации. С помощью НЛП мы можем найти нужный фрагмент среди неструктурированных данных. Информационно-поисковая система индексирует набор документов, анализирует запрос пользователя, затем сравнивает описание каждого документа с запросом и представляет соответствующие результаты.
- Группировка информации. Группировка или классификация текста выполняется с помощью текстовых тегов. Модель НЛП обучена классифицировать документы по определенным признакам: тема, тип документа, время, автор, язык и т. д. Для классификации текста обычно требуются размеченные данные. Группировка информации используется для контролируемого машинного обучения, что, соответственно, запускает множество вариантов использования.
- Анализ настроений. Это тип классификации текста, при котором алгоритмы НЛП определяют положительную, отрицательную или нейтральную коннотацию текста. Варианты использования включают анализ отзывов клиентов, выявление тенденций, проведение маркетинговых исследований и т. д. посредством анализа твитов, постов, отзывов и других реакций. Анализ настроений может охватывать все: от выпуска новой игры в App Store до политических выступлений и изменений в законодательстве.
- Ответы на вопросы. Автоматизированная система ответов на вопросы применяет набор методов НЛП для анализа неструктурированных документов — от статей Википедии до новостных лент социальных сетей или медицинских записей — путем извлечения необходимой части информации, ее анализа и использования лучшей части для ответа на вопрос.
- Автоматическое распознавание речи (ASR). Методы НЛП на самом деле предназначены для текста, но их также можно применять к устному вводу. ASR преобразует устные данные в поток слов. Нейронные сети и скрытые марковские модели используются для снижения частоты ошибок при распознавании речи, однако они все еще далеки от совершенства. Основной проблемой является отсутствие сегментации в устных документах. И в то время как слушатели могут легко сегментировать устный ввод, автоматический распознаватель речи обеспечивает неаннотированный вывод.
Ценность использования методов НЛП очевидна, а области применения обработки естественного языка многочисленны. Но таковы и проблемы, с которыми сталкиваются специалисты по данным, специалисты по машинному обучению и исследователи, чтобы сделать результаты НЛП похожими на человеческий результат.
→ Прочтите нашу статью Майкла ДеПальмы и Игоря Крыгляка о фармацевтическом производстве. Улучшение расчета риска и вознаграждения для клинических испытаний: как обработка естественного языка и машинное обучение могут повысить успех в разработке лекарств.
0003Проблемы, препятствующие массовому внедрению НЛП
Несмотря на годы исследований и более совершенный ИИ, обработка естественного языка по-прежнему непроста. Сотни языков со своими собственными синтаксическими правилами — это лишь верхушка айсберга. В каждой прикладной области есть проблемы, которые делают модели НЛП несовершенными и нуждаются в улучшении. В дополнение к проблемам, о которых мы упоминали ранее, вот некоторые из наиболее важных причин, по которым НЛП еще не стало мейнстримом:
- Схемы кодирования : текст закодирован с использованием схем ASCII, UTF-8, UTF-16 или Latin-1, которые немного отличаются назначением новых символов. Пунктуация и цифры могут нуждаться в специальной обработке НЛП. Кроме того, вы должны обратить внимание на смайлики, гиперссылки, расширения, определенные символы в именах пользователей и так далее.
- Токенизация на некоторых языках: Модели НЛП токенизируют текст, т. е. разбивают его на последовательность слов (или токенов). Однако в таких языках, как китайский, для слов, а иногда и фраз используются уникальные символы, поэтому процесс токенизации не работает так же, как с разграниченными словами.
- Генерация графов зависимостей : машины должны определять положение каждого слова в предложении на основе тегов POS и контекста. Для этого необходимо построить графы зависимостей, но процесс довольно сложный. Одно слово может принадлежать разным частям речи, либо одно ПОС может занимать разные места в предложении или тексте.
- Понимание контекста : одна из самых сложных задач для ИИ. Понимание и получение контекста требует специальных графов знаний для систем НЛП. Они также должны быть специфичными для предметной области, поэтому здесь необходимо улучшить вероятностный подход. Понимание семантики словарных терминов в контексте — еще одна проблема, которую должна решить машина.
Несмотря на эти трудности, НЛП способно достаточно хорошо выполнять задачи в большинстве ситуаций и обеспечивать дополнительную ценность во многих проблемных областях.
Хотя он недостаточно независим, чтобы обеспечить человеческий опыт, он может значительно повысить производительность определенных задач при сотрудничестве с людьми. Опыт Avenga подтверждает это утверждение.→ Откройте для себя алгоритм анализа настроений, созданный с нуля нашей командой специалистов по обработке и анализу данных.
Опыт Avenga в области НЛП в области здравоохранения
Клинические исследовательские организации могут извлечь большую выгоду из развертывания систем на основе ИИ для клинических испытаний. Они помогают преодолеть стагнацию медицинских исследований, регистрируя достаточное количество соответствующих пациентов для получения достоверных результатов испытаний, что в наши дни является огромным преимуществом.
Обработка естественного языка помогает клиентам Avenga — поставщикам медицинских услуг, медицинским исследовательским учреждениям и CRO — получать информацию, раскрывая потенциальную ценность своих хранилищ данных. Применяя функции НЛП, они упрощают процесс поиска влиятельных лиц, необходимых для исследований — врачей, которые могут найти большое количество подходящих пациентов и убедить их принять участие в испытаниях.
НЛП и машинное обучение помогают оптимизировать и упростить ежедневные операции, приносят больше пользы пациентам и обеспечивают эффективную и вознаграждающую работу персонала.
Услуги Avenga NLP включают в себя:
- Признание объекта
- Тематические кластеризации
- Экстракция ключевой фразы
- Многодокументные суммирование
- ИСПРАВЛЕНИЕ И ПРЕДЛОЖЕНИЕ БАРМИНГОВЫЕ ОБЩЕСТВЕННЫЕ ИСПОЛЬЗОВАНИЕ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ ИСПОЛЬЗОВАНИЯ. проводить свои клинические испытания с максимальной эффективностью. Если вы решите разработать решение, использующее НЛП в здравоохранении, мы будем здесь, чтобы помочь вам.
Заключение
Обработка естественного языка может принести пользу любому бизнесу, желающему использовать неструктурированные данные. Приложения, запускаемые моделями НЛП, включают анализ настроений, обобщение, машинный перевод, ответы на запросы и многое другое.
 Когда они были впервые представлены, они были не совсем точными, но благодаря многолетнему обучению машинному обучению на миллионах выборок данных электронные письма в наши дни редко попадают не в тот почтовый ящик.
Когда они были впервые представлены, они были не совсем точными, но благодаря многолетнему обучению машинному обучению на миллионах выборок данных электронные письма в наши дни редко попадают не в тот почтовый ящик.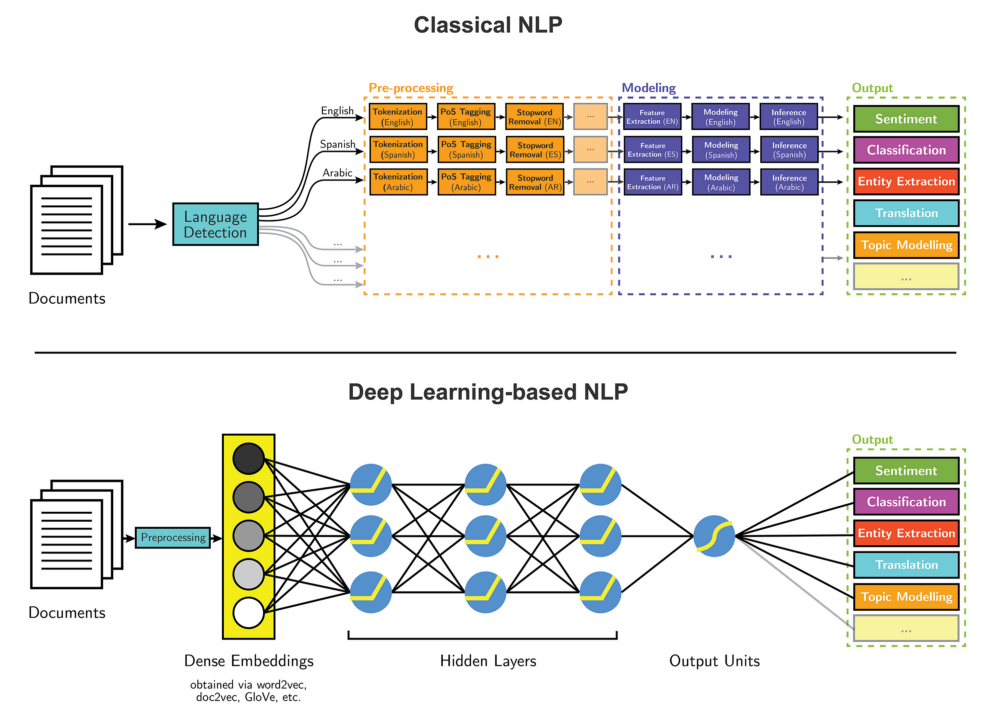
 д.) по соответствующим темам или категориям отделов.
д.) по соответствующим темам или категориям отделов. д.) означает, что компаниям необходимо иметь стратегию классификации каждого поступающего обращения.
д.) означает, что компаниям необходимо иметь стратегию классификации каждого поступающего обращения.
 Это может быть особенно полезно для суммирования больших фрагментов неструктурированных данных, таких как научные статьи.
Это может быть особенно полезно для суммирования больших фрагментов неструктурированных данных, таких как научные статьи.

 Тем не менее, его возможности только начинают изучаться.
Тем не менее, его возможности только начинают изучаться. Это отличная альтернатива, если вы не хотите тратить время и ресурсы на изучение машинного обучения или НЛП.
Это отличная альтернатива, если вы не хотите тратить время и ресурсы на изучение машинного обучения или НЛП. Существует руководство и учебник по использованию NLTK, но это довольно крутая кривая обучения.
Существует руководство и учебник по использованию NLTK, но это довольно крутая кривая обучения.

 Эта технология, которая принесет к 2025 году многообещающие 43 миллиарда долларов, заслуживает внимания и инвестиций. Как предприятия могут использовать НЛП? Каковы основные области приложений для обработки естественного языка? Имея непосредственный опыт использования НЛП в сфере здравоохранения, Avenga может поделиться своим пониманием этой темы.
Эта технология, которая принесет к 2025 году многообещающие 43 миллиарда долларов, заслуживает внимания и инвестиций. Как предприятия могут использовать НЛП? Каковы основные области приложений для обработки естественного языка? Имея непосредственный опыт использования НЛП в сфере здравоохранения, Avenga может поделиться своим пониманием этой темы.