Морфемный разбор слова онлайн – ТОП-5 сервисов
В школе часто задают выполнить морфемный разбор слова: найти основу, корень, суффикс, окончание Существуют онлайн-сервисы для морфемного разбора.
Я проверила их корректность и выбрала лучший.
| Сервис | Удобство | Полный ли словарь | Адрес |
|---|---|---|---|
| МорфемОнлайн | 5 | 5 | http://morphemeonline.ru |
| СоставСлова | 4 | 4 | http://sostavslova.ru |
| ВикиСлово | 4 | 4 | http://wikislovo.ru/ |
| Ударение | 3 | 3 | http://udarenieru.ru/index.php?word=on |
| СловОнлайн | 3 | 2 | http://slovonline.ru |
МорфемОнлайн
Самый лучший сервис, два следующих просто копируют результаты из него в сокращенном виде.
- Красиво и полно представлены результаты разбора по составу.

- Нет рекламы.
- Есть шпаргалка по разбору слова по составу – теория описана кратко и просто.
- Современный и полный словарь слов.

По поводу полноты словаря: это единственный сайт, на котором слово «онлайн» представлено аж в трех лексических значениях, и все значения прояснены. И соответственно разобрано слово тоже в трех вариантах. На большинстве сайтов этого слова либо нет, либо дано только одно значения. Не считая сайтов-копий, которые я поставила на 2-е и 3-е место соответственно. Но если честно, нет ни единой причины предпочитать другие сайты этому.
Для того, чтобы выбрать ответ, надо только определить часть речи и лексическое значение. Ведь одно и то же слово может быть сразу несколькими частями речи в зависимости от контекста.
Существительное:
Я сижу в онлайне.
Я сижу в кафе.
Наречие:
Я смотрю фильм онлайн.
Я сижу давно.
Есть шпаргалка по разбору слова по составуСоставСлова
Урезанная копия morphemeonline, где не объясняется лексическое значение слова «онлайн». Кроме того, есть реклама. Как я уже сказала, ни единой причины использовать этот сайт по сравнению с предыдущим нет.
Кроме того, есть реклама. Как я уже сказала, ни единой причины использовать этот сайт по сравнению с предыдущим нет.
Лексическое значение слов «онлайн» не объяснено, хотя оно не очевидно. Ведь есть существительное «онлайн», в котором можно сидеть. Есть наречие «онлайн»: например, смотреть «онлайн». И есть наречие «онлайн» в противоположность «офлайн», будет приставка. Во всех трех случаях разбор по составу разный.
Но не пугайтесь, если не понимаете разницу, в школьных домашних заданиях слова для разбора обычно попроще. Этот пример приведен для того, чтоб вы поняли преимущества первого сайта.
Как видите, скриншот даже не вмещает все три разбора из-за наличия рекламы.
ВикиСлово
Тоже урезанная копия morphemeonline, где не объясняется лексическое значение. Кроме того, урезано описание морфем – только картинка.
Есть дополнительный сервисы: фонетический, морфологический разбор.
ВикиСлово
Но в этом сервисе, как и во всех, кроме самого первого, больше минусов, чем плюсов. Один из них реклама.
Один из них реклама.
Есть навязчивая реклама
УдарениеРу
Словарь не полностью представлен, найдено только одно значение слова «онлайн». Разбор слова по составу представлен некрасиво, описание с сокращениями, нет картинок.
Как видите, найдено только одно основное значение слова:
Результат работы сервиса УдарениеСловОнлайн
Очень ограниченный словарь, слово «онлайн» не найдено вообще. Разбор по составу представлен некрасиво. Есть реклама, интерфейс устаревший неудобный.
Ужасный интерфейс СловОнлайнТрудно пользоваться, при поиске надо не забыть выбрать «Разбор по составу (Морфемный)» и потом щелкнуть найденное слово. Тут много словарей, но устаревших, так как наше слово в них все равно не найдено.
Разница между морфемный и морфологическим разбором
И напоследок разъясню разницу между морфемным и морфологическим разбором слова.
Морфемный разбор — это разбор по составу, тут ручкой отмечают корень, суффикс, окончание.
Что такое морфемный разбор слова youtube.com/embed/AdAWzI6PY2k?feature=oembed» frameborder=»0″ gesture=»media» allowfullscreen=»»>
youtube.com/embed/AdAWzI6PY2k?feature=oembed» frameborder=»0″ gesture=»media» allowfullscreen=»»> А при морфологическом разборе ручкой ничего не отмечают, это просто определение склонения, рода и других (зависит от слова) характеристик части речи.
Что такое морфологический разбор слова
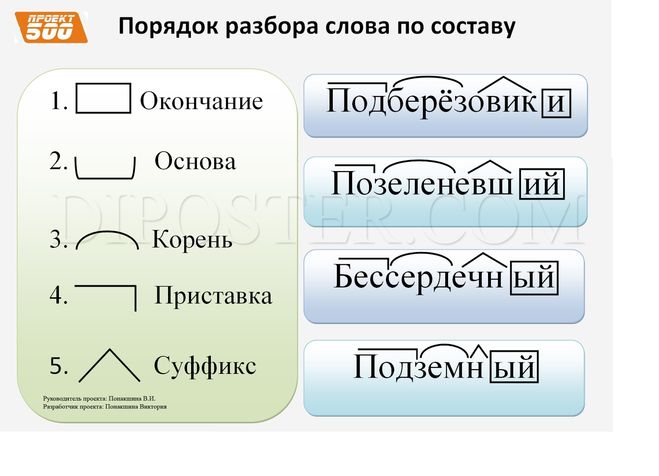
Как разобрать слово по составу?
Разобрать слово по составу следует, указав следующие морфемы: приставку, корень, суффикс, окончание, соединительную морфему, постфикс.
Окончание в составе слова
Выполнение разбора слова по составу, обычно необходимо начинать с выделения окончания, которое не входит в его основу. Для этого определим, изменяемое ли слово перед нами, есть ли у него окончание. С этой точки зрения важно, к какой части речи относится анализируемая лексема.
Помним, что у неизменяемых частей речи и форм слов нет окончания:
1. у несклоняемых существительных
у несклоняемых существительных
- драже, метро, такси, рагу, каноэ, боа.
2. У несклоняемых прилагательных
- платье миди,
- юбка гофре,
- язык ханты,
- вес нетто,
- брюки хаки.
3. У наречий на конце вычленим только суффиксы:
- быстро
- неспроста
- врукопашную
- по-польски
4. В морфемном составе деепричастий имеются формообразующие суффиксы:
- гулять — гуляя
- сбежать — сбежав
- открыть — открывши
- нести — нёсши
5. В форме простой сравнительной степени прилагательных и наречий вычленим суффиксы:
- ходить тише,
- стало радостнее,
- говорите громче.
Основа слова
Выделив окончание в изменяемом слове, которое склоняется, спрягается или изменяется по родам и числам, остальную часть лексемы обозначим как основу слова.
- создание
- красивый
- двадцатый
- отправим
Помним, что в основу слова не входят формообразующие суффиксы причастий, деепричастий, формы прошедшего времени глагола, постфикс формы повелительного наклонения глагола -те, суффиксы простой сравнительной степени прилагательных и наречий.
Примеры
- лелеющий ребенка
- вылинявшая рубашка
- видимый издали
- задуманный проект
- растертый в порошок
- гуляя по набережной
- открыв книгу
- вычертила график
- нарежьте кусочками
- шагать веселее
- стал слаще
Приставка в составе слова
Затем выделим приставку в слове, если она есть. Чтобы убедиться, есть ли эта морфема в слове, можно убрать ее и посмотреть, существует ли в лексике русского языка такое самостоятельное слово, или, второй вариант проверки, — менять предполагаемую приставку на другую:
сорвать — рвать, оторвать, надорвать, перервать, урвать.
Результативным способом определения приставки в составе слова является подбор лексем с такой же приставкой:
содрать, собрать, совместить, согласиться.
В морфемном составе лексемы может быть несколько приставок, тогда целесообразно составить словообразовательную цепочку и добраться до первого производящего слова:
небезынтересный — безынтересный — интересный.
Суффикс в составе слов
Теперь займемся суффиксом слова. Посмотрим, существует ли слово без такого суффикса:
- седина — седой,,
- вкладчик — вклад,
- бодрость — бодр, бодрый.
Подберем слова с таким же суффиксом и убедимся, что такой суффикс существует:
бодрость — нежность, весёлость, радость.
И теперь после последовательного вычленения всех морфем осталась главная часть слова — корень. Чтобы точно определить границы корня и убедиться, правильно ли мы его выделили, займемся подбором родственных слов. Как известно, общая часть родственных слов, в которой заключено основное лексическое значение слова, и есть корень.
Чтобы точно определить границы корня и убедиться, правильно ли мы его выделили, займемся подбором родственных слов. Как известно, общая часть родственных слов, в которой заключено основное лексическое значение слова, и есть корень.
Бодрость — бодрый, бодро (шагать), бодренький, бодриться.
Пример разбора слова по составу
Рассмотрим в качестве примера морфемный разбор слова «безрадостный».
Это изменяемое прилагательное, значит, вычленим окончание -ый, сравнив его формы:
- безрадостная неделя,
- безрадостное настроение,
- безрадостные новости.
Определим основу слова — безрадостн-:
безрадостный
Далее укажем приставку без-, как и в составе слов:
- бездомный
- безработный
Чтобы вычленить суффиксы в слове «безрадостный», восстановим словообразовательную цепочку:
безрадостный ← радостный ← радость ← рад (нет полной формы прилагательного).
Как видим, в составе прилагательного можем выделить суффиксы -ость-, -н-.
Оставшаяся часть слова -рад- является корнем, который прослеживается в родственных словах:
- радость
- радостный
- радовать (ся)
Закончим разбор по составу итоговой записью:
безрадостный — приставка/корень/суффикс/суффикс/окончание
Видеоуроки
Разбор глагола по составу
Как автоматически анализировать информацию о композиции и движении в классической музыке
Введение
Меня спрашивали, как я реализую автоматический анализ информации для классической музыки, совсем недавно об информации о движении и номере движения, поэтому я собираюсь попробовать чтобы объяснить немного об этом здесь. Я подумал, что будет лучше, если я представлю это вместе с полем «Композиция». Я уже говорил о композиции в предыдущем уроке, и это будет охватывать часть той же информации, чтобы быть более связным.
Во-первых, небольшая оговорка: я считаю, что часть этой работы еще не завершена. Он развивался с течением времени, и, хотя композиция хорошо определена, информация о движении более сложна и может продолжать улучшаться. Кроме того, Мэтт работает над некоторыми изменениями в языке выражений, которые я предложил, чтобы упростить определенные аспекты такого рода вещей, поэтому будут возможности упростить некоторые выражения, когда эти обновления станут общедоступными.
Итак, для интересующихся опишу систему, которой пользуюсь. Я думаю, что это хорошая система и определенно лучше, чем некоторые альтернативы, но это далеко не единственная система, которая будет работать. Если вы хотите иметь другую систему, вы можете адаптировать то, что я здесь делаю, в соответствии с тем, как вы хотите работать.
Самое важное, что нужно понять, это то, что у вас должна быть структурированная система наименования для вашей классической музыки, и вы должны применять ее. Если вы хотите, чтобы ваша информация анализировалась автоматически, ее необходимо систематизировать. Это очень важно.
Это очень важно.
Так зачем нам это? Следует понимать, что в популярной/роковой/джазовой музыке большинство музыкальных произведений представляют собой один трек, а классика отличается. Большая часть классической музыки состоит из нескольких треков, которые вместе образуют единое музыкальное произведение — композицию. Например, Первый фортепианный концерт Моцарта состоит из 3 частей, каждая из которых находится на отдельной дорожке, и вы можете слушать эти три дорожки вместе как одну композицию. JRiver изначально не имеет такой концепции композиции, поэтому я создал ее. Часто, хотя и не всегда, когда музыка записывается на CD, каждое Движение Композиции представляет собой трек. Поэтому полезно принять эту форму, и ее часто можно использовать для музыкальных произведений, которые не идеально вписываются в структуру, если мы будем осторожны с нашей системой.
Итак, давайте начнем с Первого фортепианного концерта Моцарта, который послужит типичным произведением. В нем три трека, и если мы назовем их следующим образом, то увидим закономерность:
Концерт №1 фа мажор, K. 37: I. Allegro
37: I. Allegro
Концерт №1 фа мажор, K.37: II. Andante
Концерт №1 фа мажор, K.37: III. Allegro
В названии каждой дорожки есть двоеточие. Все, что стоит перед двоеточием, является общим для всех дорожек. Все, что стоит после двоеточия, отличает этот трек от других. Этот формат часто используется в онлайновых базах данных; это довольно часто. Если я получаю треки, названия которых не имеют такого типа структуры, я использую язык выражений, чтобы привести их в соответствие с ним. Обеспечение такой последовательности приносит дивиденды.
Композиция
Все, что стоит перед двоеточием, является Композицией. Все, что после двоеточия, является информацией о движении. Таким образом, в этой системе у нас есть следующее определение:
Имя=Композиция:Часть
Номер Части указан через точку в начале Части
В приведенном выше примере мы получаем [Композицию] из
Концерта №1. фа мажор, K.37
Все три трека имеют одинаковое значение.
Этот шаблон позволяет нам автоматически определить Композицию как вычисляемое поле:
ListItem([Name],0,:)
Умная вещь в этом определении заключается в том, что если вы опустите двоеточие (у вас не будет отдельных треков, составляющих рок-песню), тогда [Composition]=[ Name] Другими словами, если двоеточие отсутствует, название трека совпадает с названием композиции. Так что, если Name=»Stairway to Heaven», тогда Composition=»Stairway to Heaven» , все просто.
Итак, вы создаете новое поле под названием «Композиция» в меню «Параметры» -> «Библиотека и папки» -> «Управление полями библиотеки», и диалоговое окно выглядит следующим образом:
Название движения
Теперь получить информацию о движении немного сложнее.
Во-первых, в MC есть два встроенных поля: [Движение] и [Номер движения]. Поскольку это встроенные поля, мы не можем изменить их тип на Расчет данных.
Вместо этого мы создаем два новых поля: [Название движения] и [Номер движения].
Используйте то же диалоговое окно, что и раньше, для [Композиции].
[Название движения] также является расчетными данными, определяемыми следующим образом:
If(IsEqual([Composition],[Name]),ListItem([Name],1,:))
По сути, если композиция отличается от имени, она принимает все, что стоит после двоеточия. Убедитесь, что у вас не более одного двоеточия.
Для трех треков, которые я показывал вам ранее, это даст названия движений:
I. Allegro
II. Анданте
III. Allegro
Движение №
Теперь мы можем также извлечь Движение №. Это еще сложнее, потому что эти данные немного больше разнятся. [Movement #] — это поле типа вычисляемых данных, определяемое следующим образом: 9.]+))#/,1,0)))
Моя система для [Движение №] ищет два разных шаблона. Во-первых, он ожидает увидеть точку в качестве разделителя. Если точки нет (точка), то поле [Движение №] будет пустым. Это подходит для фрагментов с одной дорожкой, которые не имеют движений или нескольких частей.
Это подходит для фрагментов с одной дорожкой, которые не имеют движений или нескольких частей.
Первый образец, который он ищет, — это использование «Нет». в качестве аббревиатуры, что встречается так часто, что я сделал для этого особый случай. Например:
«9 этюдов-картинок соч. 39: № 1 до минор»
Если он увидит это, он примет «№ 1» в качестве Движения №.
Второй образец, который он ищет, — это какой-то другой термин, отмеченный точкой, и в этом случае он возьмет все до точки. Некоторые примеры:
Концерт №1 фа мажор, K.37: II. Andante [Часть №] = II
Bagatelles (11) для фортепиано, соч. 119: VI. Анданте (соль мажор) [Часть №] = VI
Оркестровая сюита № 1 до мажор, BWV 1066: 1. Увертюра [Часть №] = 1
Этот подход является достаточно гибким, чтобы разумно обрабатывать музыкальные произведения, которые не соответствует стандартной парадигме записи 1 дорожка на движение.
Например, 3-я симфония Малера имеет более оперную структуру, с 6 большими частями, разделенными на 26 дорожек. Первая часть 6-й части (дорожка 21) выглядит так:
Первая часть 6-й части (дорожка 21) выглядит так:
Симфония № 3: VI-1. Лангсам. Руэволл. Empfunden [Movement #]=VI-1
Это также может работать для оперы, в которой технически есть действия и сцены, а не движения. Посмотрите на трек из «Травиаты»:
«Травиата: Акт 2, Сцена III». Соло Альфредо [Часть №]=Акт 2, Сцена III
Поскольку он ищет точку, все, что предшествует этой первой точке, будет использоваться в качестве номера движения. Если вам не нужен номер движения, не ставьте точку.
Как это выглядит
Вы можете увидеть, как все это выглядит здесь:
Мне не нужно вводить какие-либо поля «Композиция», «Название движения» или «Номер движения». Я удостоверяюсь, что мое поле [Имя] исправлено, когда я копирую или сразу после импорта, а все остальное делается автоматически. Это хорошо работает, потому что я не люблю вводить больше, чем нужно.
Вот как вы можете анализировать информацию. Когда у вас есть информация о композиции, вы можете создавать просмотры на ее основе, а также собирать сводную статистику, такую как рейтинги и продолжительность. Вот пример:
Вот пример:
Надеемся, что JRiver улучшит MC, чтобы обеспечить встроенную поддержку Composition в будущем, чтобы их можно было правильно обрабатывать в плейлистах, смарт-листах и т. д. Если вы хотите, чтобы это произошло, выскажите свою поддержку в ветка запроса функции здесь: https://yabb.jriver.com/interact/index.php/topic,128860.0.html
Люди уже давно используют подход [Композиция], но, поскольку в последнее время появился дополнительный интерес к информации о Движении, я решил опубликовать это.
В любом случае, я надеюсь, что люди сочтут это полезным, и вы сможете адаптировать эту технику к своим потребностям…
Как вы анализируете Intel Hex Record с помощью аппликативных функторов, используя библиотеку парсека haskell?
Есть ряд вещей, не включенных в ваш вопрос, которые вам нужны для использования парсека. Чтобы определить такие вещи, как startOfRecord нам нужно отключить ужасное ограничение мономорфизма. Если мы хотим написать подписи типов для чего-то вроде startOfRecord , нам также нужно включить FlexibleContexts . Нам также необходимо импортировать parsec,
Нам также необходимо импортировать parsec, Control.Applicative и Numeric (readHex) {-# LANGUAGE NoMonomorphismRestriction #-}
{-# ЯЗЫК Гибкие контексты #-}
импортировать Text.Parsec
импортировать Control.Applicative
импорт числового (readHex)
Я также собираюсь использовать Word8 и Word16 из Data.Word , поскольку они точно соответствуют типам, используемым в шестнадцатеричных записях Intel.
импорт Data.Word
На мгновение игнорируя recordData , мы можем определить, как читать шестнадцатеричные значения для байтов ( Word8 ) и 16-битных целых адресов ( Word16 ).
hexWord8 :: (Stream s m Char) => ParsecT s u m Word8 hexWord8 = toHexValue <$> count 2 hexDigit hexWord16 :: (Stream s m Char) => ParsecT s u m Word16 hexWord16 = toHexValue <$> count 4 hexDigit toHexValue :: (Num a, Eq a) => String -> a toHexValue = fst. глава . readHex
Это позволяет нам определить все фрагменты, кроме recordData .
startOfRecord = символ ':' количество байтов = шестнадцатеричное слово8 адрес = шестнадцатеричное слово16 тип записи = шестнадцатеричное слово8 контрольная сумма = шестнадцатеричное слово8
Опустив recordData , теперь мы можем написать что-то вроде вашей строки
Applicative . Приложение в стиле Аппликативный стиль записывается как <*> ( . — функциональная композиция или композиция в Категория с).строка = _ <$> startOfRecord <*> byteCount <*> address <*> recordType <*> контрольная сумма
Компилятор сообщит нам о типе дыры _ . Там написано
Найдена дыра `_'
с типом: Char -> Word8 -> Word16 -> Word8 -> Word8 -> b
Если бы у нас была функция с таким типом, мы могли бы использовать ее здесь и создать ParserT , который читает что-то вроде записи, но все еще пропускает записьДанные . Мы создадим тип данных для хранения всей шестнадцатеричной записи Intel, кроме фактических данных.
Мы создадим тип данных для хранения всей шестнадцатеричной записи Intel, кроме фактических данных.
данные IntelHexRecord = IntelHexRecord Word8 Word16 Word8 {- [Word8] -} Word8
Если мы поместим это в строку (с const , чтобы отбросить startOfRecord )
строка = const IntelHexRecord <$> startOfRecord <*> byteCount <*> address <*> recordType <*> контрольная сумма
компилятор скажет нам, что тип строка — это парсер для нашего псевдо- IntelHexRecord .
*> :t строка строка :: Stream s m Char => ParsecT s u m IntelHexRecord
Это все, что мы можем сделать со стилем Applicative . Давайте определим, как читать recordData , предполагая, что мы уже каким-то образом знаем byteCount .
recordData :: (Stream s m Char) => Word8 -> ParsecT s u m [Word8] RecordData c = count (fromIntegral c) hexWord8
Также модифицируем IntelHexRecord , чтобы было место для хранения данных.